

| Area | Key Insight |
|---|---|
| Performance | On-device inference eliminates network latency, enabling sub-50ms response times for AI tasks, a critical factor for real-time applications. |
| Privacy & Security | By processing data locally, sensitive user information never leaves the device, providing a default state of complete privacy and security. |
| Technology | Success relies on energy-efficient kernels and native runtimes optimized for mobile hardware to deliver high performance without draining battery. |
| Market Impact | This technology shifts value from centralized cloud providers to hardware and software optimizations on the edge, opening new possibilities for mobile, wearable, and IoT devices. |
| Accessibility | Local LLMs enable powerful AI features to function without a constant internet connection, drastically improving reliability and accessibility in low-connectivity areas. |
The last few years have witnessed a meteoric rise in the capabilities of Large Language Models (LLMs), transforming everything from customer service to content creation. However, this revolution has been almost entirely dependent on a centralized, cloud-based architecture. Every query, every command, every piece of data is sent to massive server farms for processing, creating inherent bottlenecks in speed and significant concerns about data privacy. As users, we've grown accustomed to the slight—and sometimes significant—delay between asking a question and receiving an answer. Industry analysis shows that a delay of even 100 milliseconds can negatively impact user engagement, yet many cloud-based AI interactions take far longer. This model, while powerful, is showing its limitations in a world that demands instant, private, and reliable intelligence. The future isn't just about making AI smarter; it's about making it faster, safer, and more accessible by bringing it out of the cloud and directly into our hands.
A new wave of innovation is rising to meet this challenge, championed by technologies designed to run powerful AI models directly on user devices. Y Combinator-backed startup Cactus is at the forefront of this movement with its Cactus v1 framework, which promises to deliver on-device LLM inference with virtually zero latency and absolute privacy. By shifting the computational workload from remote servers to the devices we use every day—smartphones, wearables, and other low-power hardware—this approach fundamentally redefines the user-AI relationship. This article explores the technological shift towards on-device inference, its profound implications for latency and privacy, and how frameworks like Cactus V1 are architecting the next generation of intelligent applications. We will dissect the core components, compare the on-device model to its cloud predecessor, and examine the vast potential it unlocks for a truly personal AI experience.
The Cloud Dependency Dilemma: Latency and Privacy Bottlenecks
The conventional wisdom for deploying large-scale AI has been simple: use the immense power of the cloud. This model has enabled rapid progress, allowing developers to leverage models with hundreds of billions of parameters without worrying about the end-user's hardware limitations. However, this dependency has created a trade-off that is becoming increasingly apparent. The first major bottleneck is latency. Every interaction with a cloud-based LLM is a round-trip journey. The user's input travels from their device, across the internet to a data center, gets processed by the model, and the response travels all the way back. This journey, subject to network congestion, server load, and physical distance, introduces a palpable delay. While acceptable for some tasks, it's a deal-breaker for applications requiring real-time interaction, such as dynamic voice assistants, augmented reality overlays, or on-the-fly language translation.
The second, and arguably more critical, bottleneck is privacy. In the cloud-centric model, user data is a commodity that must be transmitted and processed by a third party. Every personal note dictated to an AI, every sensitive business document summarized, every private health query asked—all of it leaves the user's control. While companies implement security measures, the data remains vulnerable to breaches, surveillance, and corporate policy changes regarding data usage. This paradigm forces a difficult choice upon users: sacrifice privacy for functionality. For enterprises, this risk is magnified, as transmitting proprietary data to external servers can violate compliance regulations and expose valuable intellectual property. The fundamental architecture of cloud AI creates a centralized point of failure for both security and user trust, a vulnerability that the on-device model is designed to eliminate entirely.
Introducing On-Device Inference: A Paradigm Shift
On-device—or edge—inference represents a fundamental reversal of the cloud-first AI model. Instead of sending data to a remote brain, the brain is brought directly to the device. This involves running a scaled-down yet powerful version of an LLM locally on the device's own processor, be it a smartphone's SoC (System on a Chip), a wearable's microcontroller, or an IoT gadget's dedicated AI accelerator. The core principle is data localization: the entire process, from input to output, occurs within a closed loop on the user's hardware. Nothing is sent to the cloud unless explicitly authorized by the user for other purposes, such as backups.
This shift is not merely an architectural preference; it's a strategic move to solve the inherent flaws of cloud dependency. By computing locally, on-device AI completely sidesteps the network. The internet becomes optional, not a prerequisite for intelligence. This immediately unlocks two transformative benefits. First, it offers unparalleled performance for interactive tasks, as the speed of light and network traffic are no longer limiting factors. Second, it establishes a new standard for privacy, creating a "zero-knowledge" environment where the application provider does not need to see, handle, or store user data to deliver its service. This paradigm shift paves the way for a more resilient, personal, and trustworthy class of AI applications that can operate seamlessly anytime, anywhere. Businesses looking to implement such responsive systems can explore AI-powered communication solutions that leverage this instant-response capability.
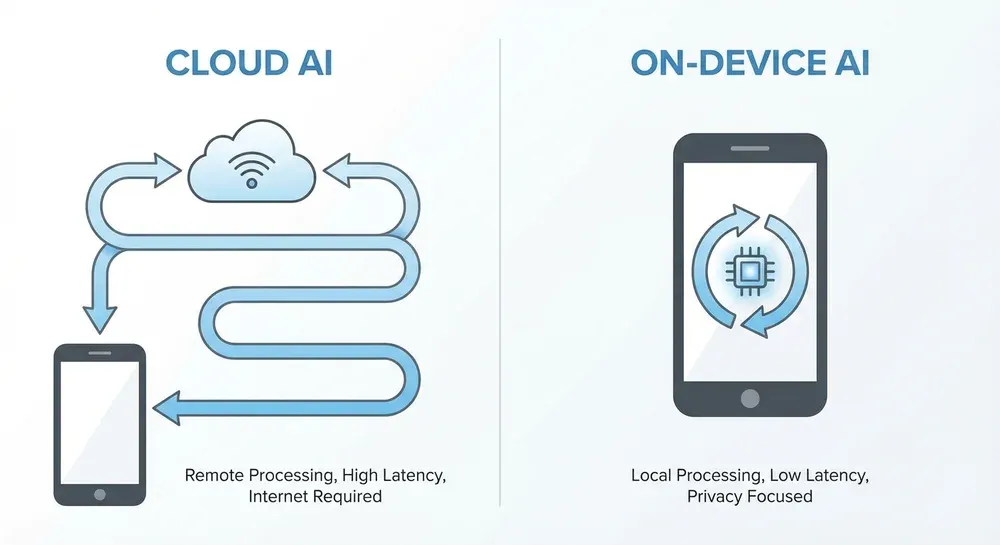
Figure: Comparison of data pathways between cloud-based and on-device AI, highlighting the elimination of network latency in the latter.
The Latency Barrier: Why Milliseconds Matter
In human-computer interaction, latency is the silent killer of user experience. Our perception of "instant" is incredibly sensitive; delays measured in fractions of a second can make an application feel sluggish, unresponsive, and unintuitive. For AI, this is especially true. A conversational AI that takes a full second to respond feels unnatural, breaking the flow of dialogue. An AR application that lags behind a user's head movement causes motion sickness. This is the problem that on-device inference directly confronts and solves.
Frameworks like Cactus V1 are engineered to obliterate network latency. The company reports a "sub-50ms time-to-first-token," a metric that represents the time taken to generate the very first piece of the model's response. This is a crucial benchmark because it reflects the immediate perceived responsiveness of the system. Achieving this speed is possible only by eliminating the data's round-trip to the cloud. By processing queries directly on the device's hardware, the only delay is the computation itself, which can be heavily optimized. This leads to interactions that feel truly real-time, enabling a new class of applications. Imagine AI-powered video filters that apply complex effects with no lag, smart assistants that provide answers as quickly as you can speak, or accessibility tools that describe the world to a visually impaired person without delay. This is not just a quantitative improvement; it's a qualitative leap that makes AI feel like a natural extension of the user's own thoughts.
Privacy by Default: The Unbreachable Fortress of Local LLMs
In an era of constant data breaches and growing concerns over digital surveillance, privacy has transitioned from a feature to a fundamental user right. The on-device AI model is architected with this principle at its core. When an LLM operates locally, sensitive information—personal conversations, financial data, health records, proprietary business documents—never has to be entrusted to a third party. It remains securely sandboxed within the user's device, under their complete control. This is what is meant by "privacy by default." It's not a setting to be enabled; it's an inherent property of the system's design.
This has profound implications for both consumers and enterprises. For individual users, it means the freedom to use AI for highly personal tasks without fear of data being mined, sold, or exposed. It fosters a level of trust that is simply unattainable with cloud-based services. For businesses, the benefits are even more significant. Industries like healthcare, finance, and legal are bound by strict data privacy regulations (e.g., GDPR, HIPAA). On-device inference allows them to leverage advanced AI capabilities while remaining fully compliant, as no protected data ever leaves the premises or the user's device. It also protects corporate intellectual property by ensuring that strategic plans, R&D data, and internal communications analyzed by an AI are not exposed to external servers. By making the user's device the ultimate perimeter, local LLMs create a robust and trustworthy security model. This principle extends to how businesses can build more secure internal tools, such as an advanced RAG chatbot for internal knowledge bases, ensuring that proprietary company data remains within the corporate firewall.

The Engine Room: Dissecting Cactus V1's Technology
Delivering high-performance LLM inference on resource-constrained devices is a formidable engineering challenge. It requires a delicate balance between computational power, energy consumption, and model size. The technology behind Cactus V1 highlights the key components needed to achieve this balance: energy-efficient kernels and a native runtime. These elements are critical for any on-device AI framework to succeed and are central to efficient data processing in a mobile environment.
Energy-Efficient Kernels
At the lowest level, a "kernel" in this context refers to a highly optimized piece of code that performs a specific computational task, such as matrix multiplication, which is a core operation in neural networks. "Energy-efficient" means these kernels are designed from the ground up to execute with the minimum possible power draw. This is achieved by writing code that takes full advantage of the specific architecture of mobile processors (e.g., ARM's NEON instructions). Instead of generic code that runs anywhere, these are bespoke routines that speak the native language of the chip, reducing wasted cycles and minimizing battery drain. This optimization is what allows a device to perform complex AI calculations without overheating or running out of power in minutes.
Native Runtime
A "runtime" is the environment that executes the AI model. A "native" runtime is one that sits very close to the hardware, without layers of abstraction or interpretation that can slow things down. Think of it as the difference between a high-performance racing engine and a standard passenger car engine. The native runtime is purpose-built to load the optimized model, manage memory efficiently, and dispatch computations to the energy-efficient kernels as quickly as possible. By being cross-platform, Cactus V1's runtime can deliver this performance consistently across different operating systems (like iOS and Android) and hardware, providing a unified and predictable development experience. This combination of specialized kernels and a lean runtime is the technical foundation that enables the sub-50ms performance and makes sophisticated on-device AI a practical reality.
On-Device vs. Cloud AI: A Comparative Analysis
The choice between on-device and cloud-based AI is not about which is universally "better," but which is suited for a specific application's needs. Each model presents a distinct set of advantages and trade-offs across several key dimensions. Understanding these differences is crucial for developers and businesses aiming to build effective and user-centric AI solutions. For many enterprises, the ideal solution often involves a hybrid approach, leveraging powerful custom automation solutions that combine the best of both worlds.
Below is a detailed comparison highlighting the primary distinctions between the two architectures.
| Factor | On-Device (Edge) AI | Cloud-Based AI |
|---|---|---|
| Latency | Extremely low (sub-50ms), limited only by local processing power. Ideal for real-time interaction. | Variable and higher, dependent on network speed, server load, and distance. Not suitable for instant feedback loops. |
| Privacy | Maximum privacy. All data remains on the user's device by default. | Lower privacy. Data must be sent to a third-party server, creating potential vulnerabilities. |
| Connectivity | Fully functional offline. AI capabilities are always available, regardless of internet connection. | Requires a stable internet connection to function. Useless without it. |
| Cost | No ongoing server costs for inference. A one-time cost for software development and integration. | Recurring operational costs based on API calls, data transfer, and server uptime. Can be expensive at scale. |
| Model Complexity | Limited by device hardware (RAM, CPU/GPU). Models must be smaller and highly optimized. | Virtually unlimited. Can run massive, state-of-the-art models with trillions of parameters. |
| Scalability & Updates | Scaling is decentralized (per device). Model updates require app updates to be pushed to users. | Centrally scalable. Models can be updated instantly on the server-side without user intervention. |

Real-World Applications and Future Frontiers
The transition to on-device inference is not just a technical upgrade; it's an enabler of entirely new user experiences and product categories that were previously impractical. The combination of speed and privacy unlocks a vast design space for innovation across consumer and enterprise sectors. In the immediate future, we can expect to see smarter, more responsive applications that feel seamlessly integrated into our daily lives. Think of a mobile keyboard that offers genuinely helpful, context-aware writing suggestions and translations instantly, without sending your keystrokes to a server. Consider smart home devices that can understand and execute complex commands in natural language without needing an internet connection, ensuring they work even during an outage.
Looking further ahead, the applications become even more transformative. In healthcare, wearables could perform real-time analysis of biometric data to provide personalized health coaching or early warnings for medical conditions, all while guaranteeing patient confidentiality. In the automotive industry, in-car assistants could offer reliable, split-second responses for navigation and vehicle control, unaffected by cellular dead zones. For accessibility, smart glasses could provide real-time descriptions of a user's surroundings, read text, and recognize faces, all processed locally to ensure both speed and the privacy of the user's life moments. As mobile hardware continues to evolve with more powerful neural processing units (NPUs), the gap between what's possible in the cloud and on the edge will continue to narrow, making the future of AI intensely personal, context-aware, and fundamentally more human-centric.
Challenges and the Road Ahead for Edge AI
Despite its immense potential, the path to widespread adoption of on-device LLMs is not without its challenges. The most significant hurdle remains the inherent resource constraints of mobile and embedded devices. Unlike the near-limitless power of a data center, a smartphone has finite memory, processing capacity, and battery life. Running a complex neural network is a power-intensive task, and doing so inefficiently can lead to poor user experience through battery drain and device overheating. This necessitates continuous innovation in model optimization techniques, such as quantization (reducing the precision of the model's weights) and pruning (removing unnecessary connections in the neural network), to shrink models without catastrophically degrading their performance.
Another major challenge lies in the development and deployment lifecycle. While cloud models can be updated centrally and instantly, on-device models are distributed across millions of individual devices. Pushing updates requires users to download new versions of an application, leading to version fragmentation and a slower rollout of improvements. Furthermore, the hardware ecosystem is incredibly diverse. Optimizing a model to run perfectly on a flagship smartphone is one thing; ensuring it performs reliably across hundreds of different mid-range and budget devices with varying chipsets and memory capacities is a much greater logistical and engineering challenge. The road ahead will require closer collaboration between model developers, hardware manufacturers, and application creators to build standardized, efficient pipelines that make developing and deploying on-device AI as seamless as its cloud counterpart.
The shift to on-device AI is creating a new competitive landscape where speed, privacy, and user experience are paramount. By leveraging localized processing, your business can deliver next-generation applications that are faster, more secure, and more reliable than ever before.
Develop Your On-Device AI StrategyFrequently Asked Questions
What exactly is on-device LLM inference?
On-device LLM inference is the process of running a large language model directly on a user's hardware, such as a smartphone or wearable, instead of sending data to a remote cloud server for processing. This approach keeps all data localized, significantly reducing latency and enhancing privacy because sensitive information never leaves the device.
What are the primary benefits of on-device AI over cloud-based AI?
The main advantages are speed, privacy, and offline functionality. On-device AI eliminates network latency, providing near-instant responses. It offers superior privacy as data is not transmitted to third-party servers. It also allows AI features to work reliably even without an internet connection, which is crucial for mobile and IoT applications.
How does a technology like Cactus V1 achieve near-zero latency?
Cactus V1 achieves its sub-50ms time-to-first-token by eliminating the biggest bottleneck: the network round-trip. By using highly optimized, energy-efficient kernels and a native runtime, it processes requests directly on the device's own processor. This local computation means the only delay is the processing time itself, not the time spent sending data to and from a distant server.
What are the main challenges or limitations of on-device LLMs?
The primary challenges are resource constraints. Mobile devices have limited processing power, memory (RAM), and battery life compared to cloud servers. This means that on-device models must be smaller and highly optimized, which can sometimes limit their complexity and capability compared to massive, server-based models. Efficient model quantization and specialized hardware are key to overcoming these limitations.
Készen állsz a saját weboldaladra?
Ingyenes konzultáció során átbeszéljük, hogyan segíthetünk vállalkozásodnak növekedni egy modern, gyors és konverzióoptimalizált weboldallal. 14 nap alatt kész, 0 Ft induló költséggel.





