In the world of big data, Apache Spark is the de facto standard for distributed processing of large datasets. However, its power is also its weakness: manually fine-tuning its hundreds of configuration parameters is a complex, time-consuming, and often frustrating task that requires deep expertise. But groundbreaking findings presented by Hina Gandhi from the Berkeley AI Research (BAIR) Lab at the Data+AI Summit on October 26, 2023, signal a new era. The research highlighted how autonomous AI agents, driven by a Multi-Agent Reinforcement Learning (MARL) model, can eliminate this complexity and independently optimize Spark clusters for peak performance and cost-efficiency without human intervention.
This technological breakthrough isn't just an incremental improvement; it's a paradigm shift in how we think about the operation of data infrastructure. We are moving away from static, human-defined rules to a dynamic, self-learning, and self-optimizing system. Instead of engineers juggling parameters like `spark.executor.memory` or `spark.sql.shuffle.partitions`, AI agents continuously monitor system metrics and proactively intervene according to real-time demands. This approach not only maximizes performance but also minimizes the waste of cloud resources, resulting in direct and significant cost savings.

The Challenge of Big Data Processing and the Spark Optimization Dilemma
Apache Spark provides organizations with incredible capabilities to process petabyte-scale datasets, but this power comes with great responsibility. The performance of a typical Spark job is influenced by hundreds of configuration parameters that have complex interactions with each other. From memory management (`spark.driver.memory`) to parallelism (`spark.default.parallelism`), every single setting can have a dramatic impact on runtime and resource consumption.
The traditional optimization process is a seemingly endless cycle of experimentation. Data engineering teams spend weeks, even months, testing different configurations, analyzing logs, and trying to find the 'sweet spot' for a given job. This process is not only slow and expensive but also extremely fragile. As soon as the data volume, density, or processing logic changes, the previously perfect configuration can suddenly become underperforming, and the cycle begins anew.
The root of the problem is that the optimal configuration is not a static state but a dynamic target. The nature of the input data, the complexity of the queries being run, and the available hardware resources are all constantly changing. It is impossible for a human to comprehend and manage this multi-dimensional problem space in real-time. This is where AI data processing agents come in, designed precisely for this dynamic, complex environment.
What Are AI Data Processing Agents and Why Do We Need Them?
AI data processing agents are autonomous software entities capable of perceiving their digital environment, making decisions, and taking actions to achieve a specific goal. Instead of following rigid, pre-programmed instructions, they use learning algorithms—in this case, reinforcement learning—to improve their performance over time. Think of them as an experienced, 24/7 data engineering team focused solely on keeping the system running optimally.
In the context of Spark, these agents consider the Spark cluster their environment. They continuously 'observe' key metrics: CPU utilization, memory usage, I/O operations, garbage collection times, shuffle operation data, etc. Based on this information, they 'decide' which configuration parameters to modify and then 'act' through the Spark API, dynamically applying these changes—even during a running job.
Why do we need this? Because the complexity of modern data architectures has surpassed the limits of human cognitive abilities. The dynamism of cloud-based, scalable systems demands a level of agility that manual processes simply cannot provide. The introduction of specialized AI agents is not a luxury but a necessity for maintaining competitiveness. They allow organizations to get the most out of their expensive cloud infrastructure while their engineers focus on tasks that create business value.
The Core Innovation: Multi-Agent Reinforcement Learning (MARL) in Apache Spark
The intelligence behind autonomous optimization is Multi-Agent Reinforcement Learning (MARL), an advanced branch of machine learning. While traditional reinforcement learning (RL) uses a single agent in an environment, MARL employs multiple, cooperating (or competing) agents, which perfectly fits the nature of distributed systems like Spark.
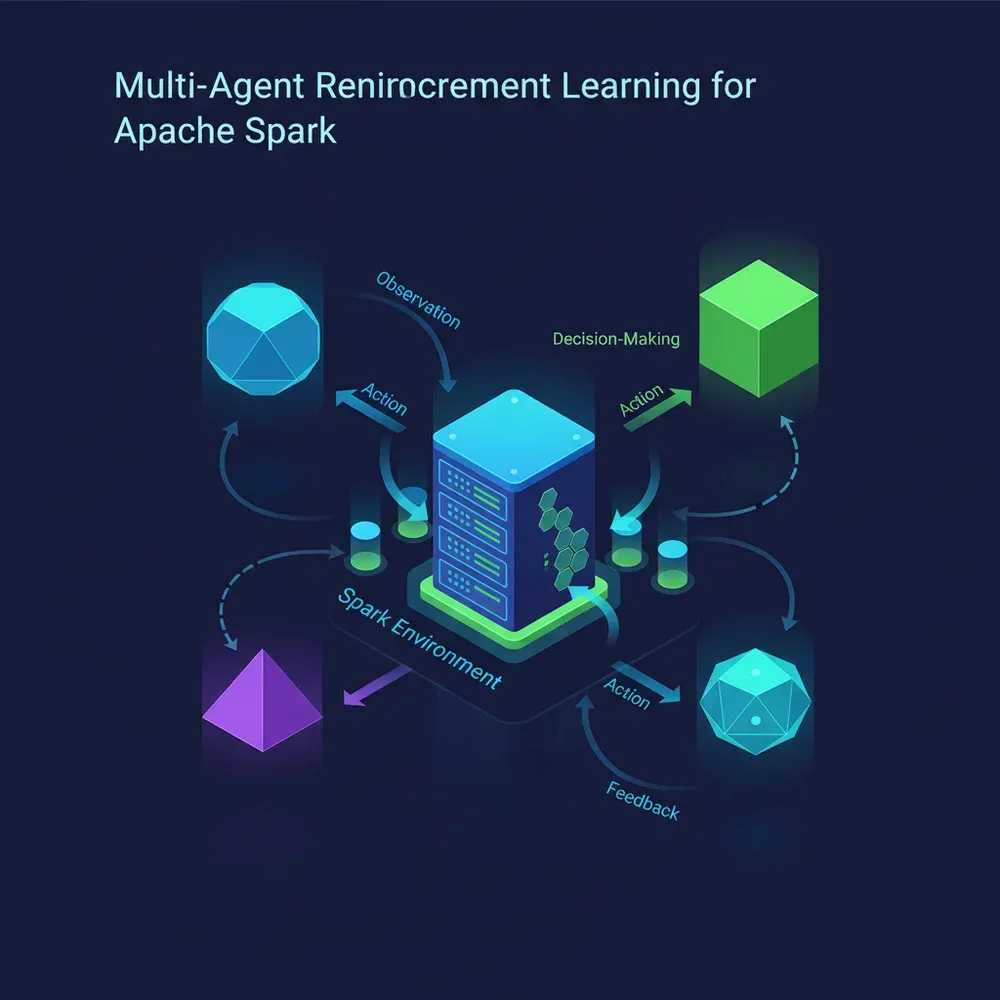
Imagine each Spark executor (the worker node) or even each major component (Driver, Executor, Shuffle Service) having its own AI agent. These agents not only monitor their own local state but also communicate with each other to make a globally optimal decision. This decentralized approach is much more robust and scalable than a single, omniscient central controller.
Reinforcement Learning Fundamentals for Optimization
Reinforcement learning is based on the principle of trial and error, similar to how humans learn. The key elements of the process in the Spark context are:
- Agent: The AI model that makes decisions (e.g., a neural network).
- Environment: The Apache Spark cluster and the data processing job running on it.
- State: A snapshot of the environment at a given moment. This is a vector containing relevant metrics (e.g., CPU load, available memory, I/O wait time, size of data to be processed).
- Action: The operation performed by the agent. This is the modification of one or more Spark configuration parameters (e.g., increase the number of executors from 10 to 15, or decrease the number of shuffle partitions from 200 to 100).
- Reward: A numerical value that gives feedback to the agent about the success of its action. The goal is to maximize the long-term cumulative reward.
For example, if an agent's action (increasing memory) leads to a decrease in job runtime, it receives a positive reward. If another action (drastically reducing parallelism) causes the job to slow down, it receives a negative reward (punishment). The agent's goal is to learn the 'policy' that selects the actions promising the highest reward in given states.
Agent Architecture: Observers, Learners, and Actuators
A typical MARL system for Spark consists of three main components:
- Observers: These components are responsible for collecting Spark metrics. They connect to the Spark UI, metric systems (e.g., Prometheus, Ganglia), and log files to gather raw data about the cluster's state.
- Learners: This is the core of the system. Based on the state data from the observers and the rewards received for previous actions, the learner (typically a distributed neural network) updates its decision-making policy. This training happens continuously in the background.
- Actuators: When the learner makes a decision (an action), the actuator is responsible for implementing it. This component modifies the necessary configuration parameters via the Spark API or the cluster manager (e.g., YARN, Kubernetes).
The Role of the Environment and Reward Functions
The reward function is the most critical element of the system, as it defines what 'optimal' operation means. The reward function must be aligned with business goals. It is usually a weighted combination of several objectives:
Example Reward Function:
`Reward = w1 * (1 / Runtime) - w2 * (CPU_Utilization * Price) - w3 * (Memory_Utilization * Price)`
Here, `w1`, `w2`, and `w3` are weights that can be used to set business priorities. If speed is the most important, `w1` will be the largest. If cost reduction is the goal, `w2` and `w3` will be given more weight. The agents learn how to balance these often-conflicting goals to achieve the best compromise.
How AI Agents Autonomously Optimize Spark Configurations
The autonomous optimization process is a continuous, closed-loop cycle that never stops. Instead of setting up the system once and hoping for the best, AI agents constantly fine-tune it to adapt to changing conditions.

Data Collection and Feature Engineering from Spark Metrics
The first step is to collect relevant data. The agents monitor not only basic metrics (CPU, memory) but also deeper, Spark-specific information:
- Stage and Task metrics: Runtime of individual processing stages and tasks, data spill (writing from memory to disk), shuffle read/write sizes.
- Garbage Collection (GC) statistics: The frequency and duration of GC runs, an important indicator of memory pressure.
- Executor states: Logging the addition, removal, and potential failures of executors.
- Data source metrics: The amount of data read and written, the number of partitions.
From this raw data, the system creates 'features' that better describe the system's state. For example, instead of just looking at the GC time, it might calculate the 'ratio of GC time to total runtime,' which is a much more informative metric.
Model Training and Policy Learning in Configuration Spaces
Based on the collected and processed data, the AI model (the 'learner') begins to map the vast configuration space. The model's goal is to learn the relationship between states, actions, and the resulting rewards. In essence, it learns a complex function that predicts which action in a given state will result in the highest future reward.
In the initial phase, the agents do more 'exploration,' trying out more random actions to gather as much experience as possible about different parts of the configuration space. Over time, as the model becomes more confident, it shifts to the 'exploitation' phase, where it prefers the best-learned actions. This exploration-exploitation dilemma is a fundamental concept in reinforcement learning.
Dynamic Configuration Adjustment in Real-Time
The most spectacular part of the process is the real-time intervention. When the model chooses an action it deems optimal, the actuator component immediately applies it. Modern versions of Spark support the dynamic, on-the-fly modification of many key parameters. These include:
- Dynamic Resource Allocation: The agent can increase or decrease the number of executors based on the workload. If a job reaches an intensive shuffle phase, the agent can request more executors and then release them at the end of the phase.
- Adaptive Query Execution (AQE): The agent can influence AQE's decisions, for example, by optimizing the number of shuffle partitions at runtime or changing join strategies.
- Memory Management: The agent can fine-tune memory allocation between execution and storage, depending on whether the job is compute-intensive or data-intensive.
This continuous feedback loop—observe, decide, act, reward—allows the system to adapt and improve on its own, without human supervision.
Key Benefits: Performance, Cost, and Operational Efficiency
The introduction of autonomous Spark optimization is not just a technical curiosity; it brings serious business benefits. The effects are felt at almost every level of the organization, from financial statements to the daily work of engineers.
Accelerating Data Throughput and Reducing Latency
The most direct benefit is the performance increase. By always tailoring the configuration to the current workload, AI agents eliminate the bottlenecks that plague manually configured systems. Research from Berkeley and other industry case studies show that MARL-based optimization can reduce the average runtime of Spark jobs by as much as 30-45%. This means faster data analysis, fresher reports, and lower latency for real-time applications.
Significant Cost Savings on Cloud Infrastructure
In the cloud, performance is closely linked to cost. Shorter runtimes mean less consumption of computing resources (vCPU-hours). More importantly, the agents manage resources intelligently. Instead of maintaining an expensive cluster sized for peak load for an entire job, they dynamically scale resources up and down. This 'right-sizing' prevents waste, which is one of the biggest sources of cloud costs. Experience shows that organizations can achieve savings of up to 50-60% on their Spark-related cloud bills. In the age of expensive AI infrastructure, this is a key competitive advantage.
Freeing Up Engineering Resources for Strategic Work
Perhaps the most valuable, though harder to quantify, benefit is the more efficient use of human capital. Highly skilled and expensive data engineers and DevOps professionals spend a significant portion of their time on reactive troubleshooting and performance tuning. Autonomous optimization takes this burden off their shoulders. Instead of digging through configuration files and logs, engineers can focus on developing business logic, integrating new data sources, and maximizing the value derived from data. This not only increases productivity but also improves employee satisfaction, as professionals can focus on creative, higher-value tasks.
Real-World Applications and Use Cases
AI-driven Spark optimization is not a theoretical concept; it is already proving its value in many areas where large data volumes and fast processing are critical.

Optimizing ETL Pipelines and Data Warehousing
Extract, Transform, Load (ETL) processes are the backbone of modern data infrastructures. These jobs often process large but variable-sized batches of data. AI agents can recognize whether a smaller or larger amount of data has arrived on a given day and scale the resources accordingly. This ensures that data warehouses are always updated on time, in line with service level agreements (SLAs), without wasting resources during quieter periods.
Scaling Machine Learning Model Training
Training machine learning models, especially deep learning models, is extremely computationally intensive. Spark is often used to preprocess terabyte-sized training datasets and distribute model training. Here, AI agents are key to minimizing training time. They can optimize data partitioning and memory management to ensure that GPUs or other accelerators never wait for data, drastically shortening the model development cycle.
Real-time Analytics and Stream Processing
Spark Streaming and Structured Streaming enable the real-time processing of continuously arriving data. For such applications (e.g., fraud detection, real-time recommendation systems), latency is critical. AI agents continuously monitor the speed of the incoming data stream and the state of the processing chain. If the system starts to fall behind, they automatically allocate more resources to reduce latency, ensuring the reliability of real-time data processing.
Challenges and Considerations in Implementing MARL for Spark
Although MARL-based optimization holds immense promise, its implementation is not trivial. Organizations need to be aware of the technical and operational challenges before embarking on such a project.
Complexity of Distributed RL Systems
Building and maintaining a MARL system is itself a complex distributed systems engineering task. It requires a robust metric collection pipeline, a scalable model training infrastructure, and reliable actuator mechanisms. The system must be fault-tolerant and handle situations like network problems or node failures.
Data Security and Governance
The optimizing agents need deep access to the Spark cluster's metrics and control plane. This raises security issues, especially in environments working with sensitive data. Proper access control, auditing, and ensuring that agents cannot access the content of the data itself, only metadata and performance indicators, must be ensured.
Integration with Existing Infrastructure
Most organizations already have mature CI/CD pipelines, monitoring systems (e.g., Datadog, New Relic), and cluster management tools (e.g., Kubernetes, YARN). The AI optimization system must be seamlessly integrated into these existing tools to avoid creating another isolated silo. This requires careful planning and API-level integration.
Expert Insights: What the Data Says About MARL in Spark?
The effectiveness of the technology is best supported by impartial, scientific research and the opinions of industry experts. The results presented by Hina Gandhi at the Data+AI Summit 2023, mentioned earlier, are a milestone in this field.
Gandhi and her team not only confirmed the performance increase but also showed that the MARL system adapts much better to unexpected workload changes. While the performance of static configurations degraded drastically when the nature of queries or data changed, the AI agents learned the new pattern within a few cycles and re-optimized the system. This robustness and adaptability are what make the technology truly revolutionary.
The Future of Autonomous Data Processing: Beyond Spark
Although the current focus is on Apache Spark, the principles of autonomous, AI-driven optimization are applicable much more broadly. This technology can transform the fundamental operation of the entire data infrastructure stack.
In the future, similar AI agents could optimize databases (e.g., automatically creating and dropping indexes), messaging systems (e.g., dynamically adjusting Kafka partitions and replication factors), and the entire cloud infrastructure (e.g., selecting the most cost-effective virtual machine types in real-time). The ultimate goal is a fully autonomous, self-driving data center where human operators define high-level business goals, and a system of AI agents takes care of achieving those goals most efficiently.
This vision aligns with the growing role of autonomous data processing AI agents in corporate strategies, where the goal is to automate complex systems and minimize human intervention.
Ready to Future-Proof Your Data Infrastructure?
AI-driven optimization is no longer a distant future. The technology has matured, and early adopters are already gaining a significant competitive advantage. The question is no longer whether to introduce autonomous systems, but when and how.
For AI engineers, data architects, and technology leaders who want to get the most out of their big data investments, now is the time to act. Every engineering hour wasted on manual tuning is a lost opportunity. Introducing autonomous optimization not only reduces costs and increases performance but also creates a more agile, flexible, and future-proof data infrastructure.
Conclusion: The Dawn of Self-Optimizing Data Systems
The era of manual Apache Spark optimization is coming to an end. The emergence of AI agents based on Multi-Agent Reinforcement Learning opens a new age in data processing—the age of intelligent, autonomous, and self-optimizing systems. This technology not only takes Spark's performance and cost-effectiveness to a new level but also fundamentally changes the role of the data engineer, freeing professionals from repetitive, low-value tasks.
As Hina Gandhi's research has highlighted, the question is no longer whether AI can manage complex systems better than humans, but how quickly organizations can adapt this transformative technology. Those who act now will be the winners of the future in an increasingly data-driven world.
Frequently Asked Questions
How does MARL differ from traditional Spark optimization techniques?
Traditional techniques (e.g., manual tuning, heuristics) are static and reactive. They optimize for a specific, known workload and cannot adapt to changes. In contrast, MARL is a dynamic, proactive approach. AI agents continuously learn from real-time data and modify the configuration on the fly as the system state changes, always keeping the system in a state that best meets the current goals (e.g., speed, cost).
What are the prerequisites for implementing AI data processing agents in Spark?
A successful implementation requires three main things: 1) A robust metric collection system that provides detailed, real-time data on the Spark cluster's operation. 2) A modern version of Spark that supports dynamic configuration of key parameters. 3) A platform or framework for training and running reinforcement learning models that can be integrated with the existing infrastructure.
Can AI agents optimize for both performance and cost simultaneously?
Yes, this is one of their biggest advantages. The reward function can be defined to take both goals into account. For example, the reward can increase with speed but decrease with the cost of the resources used. The agent learns to find the optimal balance between the two, often conflicting, goals according to business priorities. This weighting can be fine-tuned by the system operators.
Is Multi-Agent Reinforcement Learning secure for sensitive enterprise data?
Yes, properly implemented systems are secure. The optimizing agents do not need access to the content of the processed data. They work exclusively with system metadata and performance metrics (e.g., how much data a task wrote, how long it ran, how much memory it used). With proper access control (e.g., IAM roles), it can be ensured that the agents only access the control and monitoring APIs essential for their operation.
What kind of expertise is needed to deploy and manage these agents?
Implementation typically requires a multidisciplinary team including a data engineer (with Spark expertise), an MLOps/DevOps engineer (infrastructure and automation), and a machine learning specialist (RL modeling). However, more and more managed platforms and services are emerging that aim to abstract away much of the complexity, allowing for easier adoption of the technology without having to build a full RL research team.
How long does it take to see tangible results from autonomous Spark optimization?
Results can appear relatively quickly. After the initial training phase (when the agent explores the environment), which can last from a few days to a week or two depending on the complexity of the jobs, the system already starts making intelligent decisions. Most organizations see a reduction in runtimes and cost savings within the first month, which continues to improve over time as the agent gathers more experience.
What are the potential risks or downsides of relying on AI for Spark configuration?
The main risk is the apparent loss of control and the 'black box' nature of the system. It is important that the system has guardrails to prevent the agent from applying extreme configurations that could endanger system stability. Additionally, detailed monitoring and logging are essential so that human operators can always understand why the AI made a particular decision. In the early stages, it may be advisable to run the system in 'shadow mode,' where the agent makes recommendations, but human approval is still required for execution.
Készen állsz a saját weboldaladra?
Ingyenes konzultáció során átbeszéljük, hogyan segíthetünk vállalkozásodnak növekedni egy modern, gyors és konverzióoptimalizált weboldallal. 14 nap alatt kész, 0 Ft induló költséggel.