TL;DR: RAG AI Chatbots with LinkedIn's Cognitive Memory Agent (CMA)
Despite the rapid advancement of artificial intelligence, the enterprise sector has long struggled with a fundamental problem: the "amnesia" of AI models. LinkedIn's latest breakthrough, the Cognitive Memory Agent (CMA), provides a direct answer to this challenge.
The recently published research paper highlights that merely increasing the context window is not enough to achieve true intelligence. The CMA proposes a structured memory system capable of distinguishing between past events, factual knowledge, and action patterns.
This technological leap not only increases the accuracy of RAG AI chatbots but also elevates the user experience to a whole new level. The system can remember preferences from weeks ago while processing massive enterprise databases in seconds.

What is a RAG AI Chatbot and Why Do You Need One?
Retrieval-Augmented Generation (RAG) technology is the most important innovation of recent years in the practical application of Large Language Models (LLMs). But what exactly is it?
Traditional LLMs (like the base models of ChatGPT) have a static knowledge base that is "frozen" at the time of their training. They do not know your company's internal policies, current inventory, or the latest industry news.
In contrast, an AI Chatbot (RAG) can extract information from external databases in real-time and use it during response generation. This process consists of two main steps: Retrieval and Generation.
Definition: RAG (Retrieval-Augmented Generation)
An AI architecture that combines the generative capabilities of Large Language Models (LLMs) with a dedicated information retrieval system. Instead of relying on the model's own (potentially outdated or inaccurate) internal weights, RAG first searches for relevant documents in an external database (e.g., a vector database), and then passes this information as context to the LLM to formulate an accurate, fact-based response.
Implementing RAG systems drastically reduces so-called "hallucinations"—instances where the AI confidently states falsehoods. Because the answers are based on specific, retrieved documents, the sources can always be verified.
However, in an enterprise environment, mere fact retrieval is often not enough. Users expect the chatbot to remember previous interactions, understand complex relationships, and be able to execute multi-step tasks.
This is where we hit the limitations of traditional RAG systems, which can mostly only keep the last few messages in their memory. The revolution of enterprise knowledge management requires rethinking memory management.

Challenges of RAG AI Chatbots: The Short-Term Memory Problem
As impressive as today's RAG systems are, they struggle with a serious architectural hurdle: the limitations of the context window. Although the latest models (like Gemini 1.5 Pro or Claude 3 Opus) have massive context windows of up to millions of tokens, this does not solve the memory problem.
Why? First, processing massive context windows is extremely expensive and slow. With every single message exchange, the entire previous conversation and the retrieved documents must be sent back to the model.
Second, research (such as the famous "Lost in the Middle" study) has shown that LLMs tend to forget or ignore information located in the middle of a long context. They focus only on the beginning and the end.
"The true breakthrough in artificial intelligence will not be brought about by increasing the size of models, but by making memory management intelligent." – excerpt from the LinkedIn CMA research.
Traditional RAG systems use vector databases for semantic search. This works perfectly if the question refers to a specific document (e.g., "What is the company's vacation policy?").
However, it fails if the question requires implicit context (e.g., "Based on the project mentioned last week, when do I need to submit the report?"). The vector database does not understand temporality, nor the complex relationship between the user and the project.
This is known as architectural amnesia, which leads to a frustrating user experience and inaccurate answers. LinkedIn engineers realized that modeling the functioning of the human brain could be the solution.
Introducing the LinkedIn Cognitive Memory Agent (CMA) Architecture
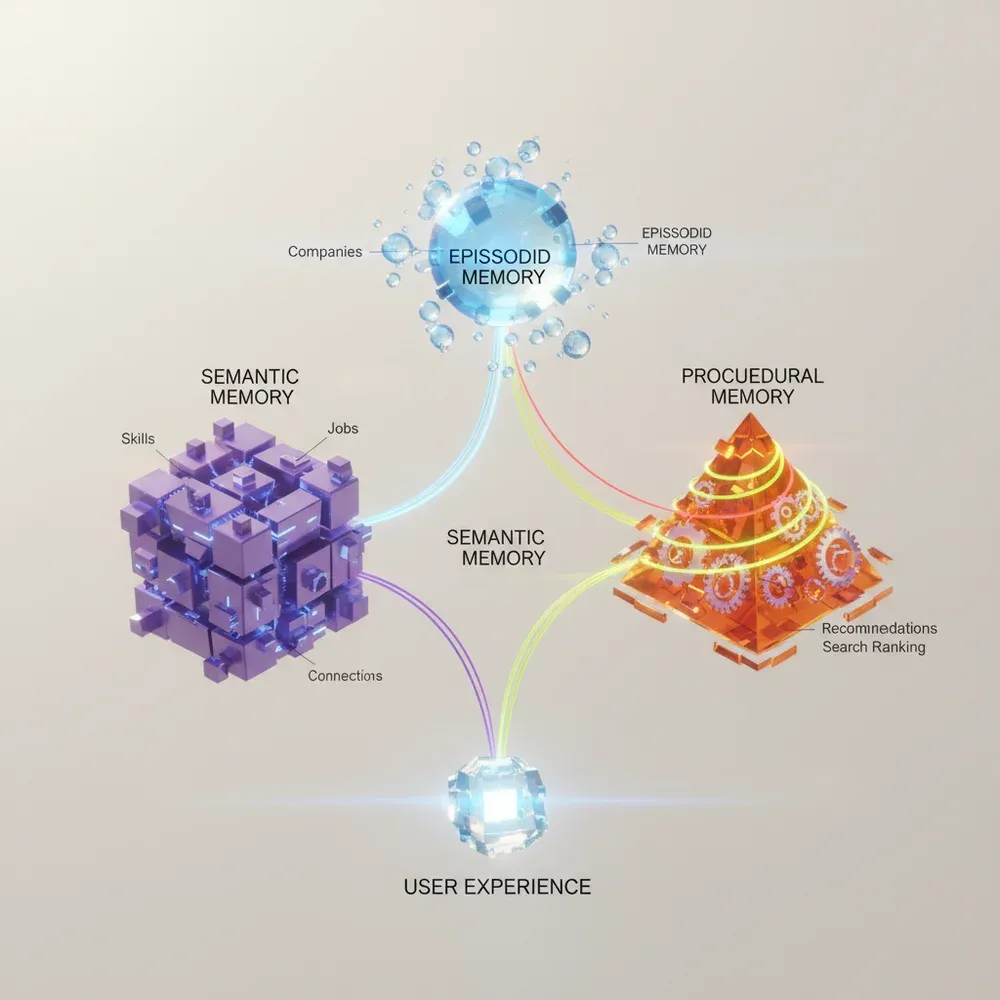
The Cognitive Memory Agent (CMA) developed by LinkedIn is a paradigm-shifting approach. Instead of dumping all information into a single massive database, CMA breaks memory down into three distinct yet cooperating layers.
This model is inspired by cognitive psychology, which categorizes human memory similarly. The goal of CMA is for AI agents not just to "read" from data, but to truly "remember" context and processes.
The LinkedIn model proves that structured memory management is essential for building scalable and reliable enterprise AI systems.
The Three-Tiered Architecture of CMA
- Episodic Memory: A log of past events, interactions, and conversations. It stores time-stamped, sequential data.
- Semantic Memory: A network of factual knowledge, concepts, and relationships between entities. It is usually implemented as a Knowledge Graph.
- Procedural Memory: The rule system for actions, workflows, and API calls. This tells the agent how to execute a task.
When a user asks a question, the CMA decides through a complex orchestration layer (such as LangGraph or AutoGen) from which memory layer to retrieve information.
Often, the combined use of all three layers is required. For example, if the user asks: "Send the summary of yesterday's meeting to the marketing team", the system retrieves yesterday's meeting from the episodic memory, identifies the members of the marketing team from the semantic memory, and retrieves the email sending process from the procedural memory.
This synergy makes the CMA orders of magnitude more intelligent and efficient than traditional RAG systems.
The Role of Episodic Memory in RAG AI Chatbots
Episodic memory is the AI agent's personal diary. This layer is responsible for recording previous interactions with the user, context, and temporal events. Without it, the chatbot would start with a clean slate with every single message.
In traditional systems, this is often solved with a simple memory buffer that retains the last 5-10 messages. However, CMA's episodic memory is much more sophisticated. It stores not only raw text but also intents, emotions, and key events extracted from the conversation.
Technically, this is often implemented with a combination of a time-series database and a vector database. Each entry receives a timestamp and an embedding, allowing for fast semantic and time-based search.
- Stateful conversations: The user can return to a topic started weeks ago, and the AI immediately picks up the thread.
- Contextual resolution: If the user says, "apply this to the previous project", the episodic memory identifies which project is being referred to.
- Time-weighted retrieval: The system can consider more recent information as more relevant, but is also capable of surfacing older, critically important data.
Imagine a customer service situation. A customer complains about a product. Two weeks later, they write again saying, "I still haven't received the replacement part".
A traditional chatbot wouldn't understand what they are talking about. CMA's episodic memory, however, immediately connects the new message with the complaint from two weeks ago, retrieves the ticket number, and provides a relevant answer. This is also the foundation of a professional AI Phone Customer Service.
Semantic Memory Operation and Benefits
While episodic memory answers the "when" and "what happened" questions, semantic memory focuses on the "what is it" and "how does it relate" questions. This layer is the system's objective, factual knowledge base.
In LinkedIn's CMA architecture, semantic memory is typically implemented using Knowledge Graphs. Unlike vector databases, which measure the statistical similarity of texts, knowledge graphs build explicit relationships between entities.
These relationships are stored in a so-called triplet format: Subject - Predicate - Object (e.g., "John Smith" - "works in" - "Marketing Department"). This structure allows for queries requiring complex, logical reasoning.
"Integrating GraphRAG (Graph Retrieval-Augmented Generation) into semantic memory can drastically reduce the rate of factual errors (hallucinations) by up to 70% in complex enterprise queries."
When a RAG AI chatbot uses semantic memory, it can see across enterprise silos. If asked: "Which projects are currently being worked on by developers who know React?", the system provides an accurate answer through graph traversal.
Semantic memory is continuously updated. Data processing AI agents read incoming documents in the background, extract new entities and relationships from them, and then insert them into the knowledge graph.
This dynamic knowledge building ensures that the chatbot always possesses the latest and most accurate enterprise information, eliminating the obsolescence problems of static RAG systems.

Procedural Memory: Tricks for RAG AI Chatbots
The third, and perhaps most exciting layer, is procedural memory. This layer enables the chatbot to transform from a passive information provider into an active doer. It stores the "how".
Procedural memory is essentially a tool repository and a collection of their instruction manuals. It contains the syntax of API calls, the steps of workflows, and error-handling protocols.
When the user requests an action (e.g., "Create a new Jira ticket about the login error"), the CMA turns to the procedural memory. It retrieves the Jira API authentication method, the list of mandatory fields, and the JSON payload structure.
Benefits of Procedural Memory
It allows the integration of custom automation directly into the chat interface. The AI agent can autonomously navigate between enterprise software (ERP, CRM, HR systems), modify data, send emails, or even execute code, all under strict access control.
LinkedIn's research highlights that separating procedural memory from the language model increases system stability. Instead of the LLM having to keep all API documentation in its context window, it only receives the relevant "recipe" at the moment of execution.
This layer also enables the orchestration of complex, multi-agent systems. Procedural memory defines which specialized agent (e.g., coding agent, data analysis agent) should step into the process, when, and how.
The evolution of the RAG chatbot clearly points towards autonomous, actionable agents, which are based on robust procedural memory.
The Impact of CMA on RAG AI Chatbot Performance
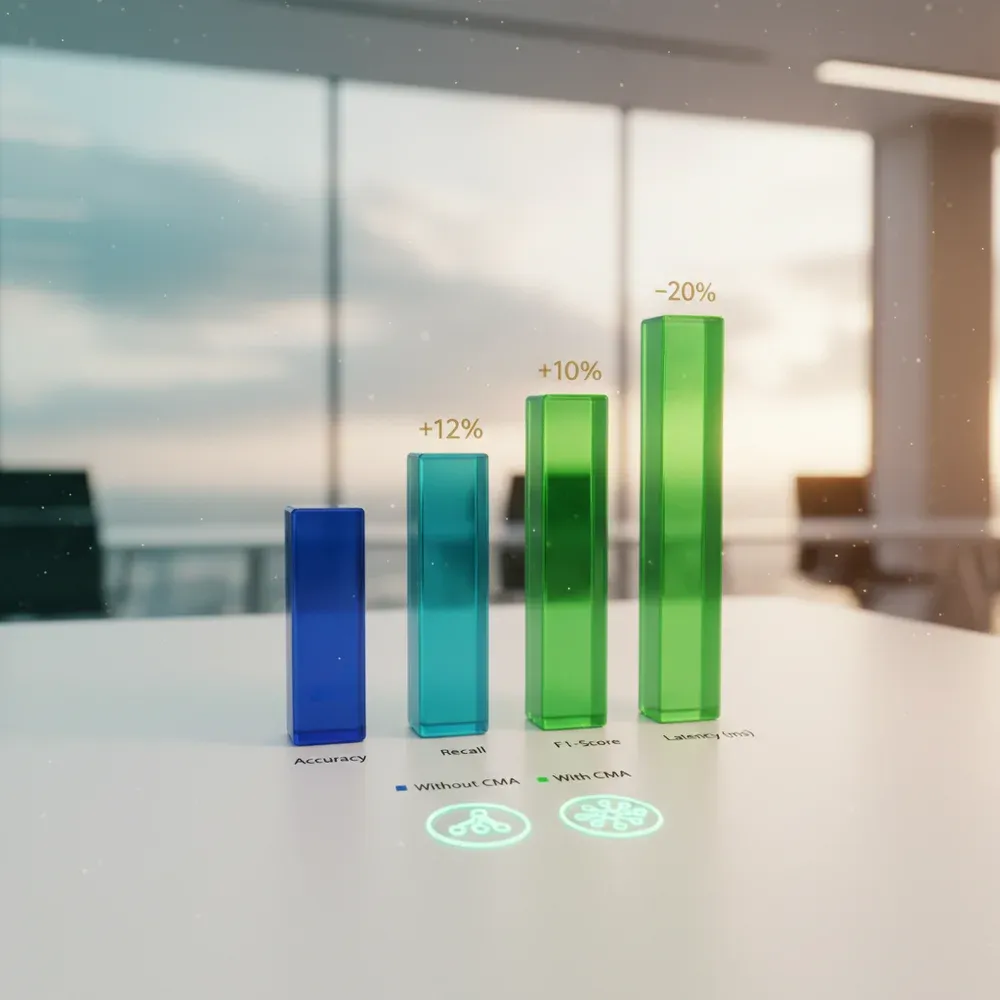
The implementation of LinkedIn's CMA architecture is not just a theoretical curiosity; it brings dramatic, measurable improvements in the performance of RAG systems. Research results and industry benchmarks clearly prove the superiority of the technology.
The most important metric is the reduction of hallucinations. Because CMA validates facts through semantic memory (knowledge graph) and gains precise context from episodic memory, the model invents false information much less frequently.
According to benchmarks, in complex, multi-hop queries, the accuracy of CMA-based systems can exceed that of traditional, vector-only RAG systems by up to 40-50%.
- Increased Recall: The system is much more likely to find relevant information in massive databases through graph-based search.
- Faster Response Time: Although the architecture is more complex, targeted memory search means the LLM has to process less unnecessary data, reducing generation latency.
- Cost Efficiency: Using smaller, optimized context windows significantly reduces API call costs (token cost).
Another critical performance indicator is user satisfaction. Stateful, remembering chatbots provide a much more natural and frustration-free experience.
Users do not have to explain their problem over and over again, which increases system acceptance and Daily Active Users (DAU) in the enterprise environment.
How to Integrate CMA into Your RAG AI Chatbot Projects
Implementing the CMA architecture is a serious engineering task, but modern AI frameworks (like LangChain, LlamaIndex, or LangGraph) significantly ease the process. Let's look at the steps!
1. Infrastructure Setup: You will need a vector database (e.g., Pinecone, Weaviate, Qdrant) to store episodic memory embeddings. For semantic memory, a graph database (e.g., Neo4j) is the ideal choice.
2. Implementing Episodic Memory: Every user interaction must be saved to the database with a timestamp, user ID, and the vector representation of the text. During retrieval, semantic similarity must be combined with temporal relevance (time-weighted vector search).
Tip for Developers: Orchestration
Use a state-based orchestrator like LangGraph. Create separate nodes to query the memory layers. A central "Routing Agent" can decide based on the user's question which memory layer needs to be activated, thus optimizing performance and token usage.
3. Building Semantic Memory (Knowledge Graph): This is the most complex step. Using data processing AI agents, enterprise documents must be processed, entities (NER - Named Entity Recognition) and relationships extracted, and then loaded into Neo4j.
4. Defining Procedural Memory: Create a registry of available Tools. Define the API schemas (OpenAPI specifications) and the execution logic. Pass only the function descriptions (Function Calling) to the LLM, and perform the actual execution in a secure, isolated environment.
AiSolve's expert team builds exactly such complex, CMA-based architectures. If you want to avoid the pitfalls, it is worth entrusting the design and execution to professionals.
E-E-A-T in RAG AI Chatbots: What's the Key to Reliability?
In enterprise AI systems, technological prowess alone is not enough; the system must be reliable. Google's E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) principles are excellently applicable to the quality assurance of RAG AI chatbots as well.
Trustworthiness is the most important pillar. The CMA architecture provides transparency. When the chatbot answers, it can show exactly from which graph node of the semantic memory, or from which previous conversation of the episodic memory, it took the information.
This kind of Explainable AI (XAI) is critical in the financial, legal, or healthcare sectors, where an incorrect AI response can have severe consequences.
"Data quality determines AI quality. Even the most advanced CMA architecture is only as good as the data fed into its semantic memory is clean and structured."
Expertise lies in procedural memory. The chatbot must not only know the answer but also be able to execute it professionally, adhering to enterprise protocols and security regulations.
Integrating robust Role-Based Access Control (RBAC) into the memory layers ensures that users only access information and functions they are authorized for. This is the foundation of secure enterprise AI deployment.
The Future of RAG AI Chatbots: The Evolution of CMA
LinkedIn's CMA architecture is just the beginning. As technology evolves, memory layers will become increasingly sophisticated and integrated. The RAG systems of the future will be fully multimodal.
Imagine that episodic memory can process and store not only text messages but also images uploaded by the user, audio files, or even screen-sharing videos. The system will remember that "based on the chart shown in last week's video call...".
Semantic memory will increasingly evolve into global, shared knowledge graphs, where AI agents from different departments of the company collaboratively build and update the company's collective knowledge base in real-time.
- Predictive Memory: The AI will not only remember but also foresee user needs based on procedural and episodic patterns, and act proactively.
- Federated Learning: Memory systems will be able to learn from each other without sharing sensitive raw data, increasing data privacy.
- Hardware-level optimization: New types of chips (e.g., LPUs) will emerge, specifically designed to accelerate graph-based memory search and RAG processes.
Companies that recognize the importance of advanced memory management in time and implement architectures similar to CMA will gain an unassailable competitive advantage in the market.
Ready for a Revolutionary RAG AI Chatbot?
The era of traditional, forgetful chatbots is over. If you want your company to step to the next level with a truly intelligent AI assistant that understands context and automates processes, the CMA architecture is the solution.
The AiSolve team is at the forefront of developing state-of-the-art RAG systems and AI agents. We do not offer boxed solutions; we build secure and scalable architectures tailored to the unique needs of your business.
Level up your enterprise efficiency! Discover our AI Chatbot (RAG) service, or request a free consultation, and let's design your future-proof AI strategy together!
Frequently Asked Questions (FAQ)
What is the main difference between RAG AI chatbots and traditional chatbots?
Traditional chatbots operate based on pre-written rules (decision trees) or use a static, trained language model that does not know the latest or internal enterprise data. In contrast, RAG (Retrieval-Augmented Generation) AI chatbots can search the company's own documents and databases in real-time and use this information to generate accurate, fact-based, and up-to-date answers, significantly reducing the chance of hallucinations.
How does CMA improve the accuracy of RAG AI chatbots?
CMA (Cognitive Memory Agent) breaks memory down into three layers: episodic (past interactions), semantic (factual knowledge graph), and procedural (action rules). This structured approach allows the system to accurately understand context, remember previous conversations, and find logical connections between data. Thus, the model does not get lost in massive context windows and provides much more precise, relevant answers.
What are the advantages of the CMA architecture compared to traditional RAG systems?
Traditional RAG typically only uses vector search, which is good for finding documents but weak at understanding complex relationships and temporality. CMA understands relationships between entities through knowledge graphs (semantic memory) and enables stateful conversations through episodic memory. Furthermore, through procedural memory, it is capable of autonomous task execution, which standard RAG cannot do.
What infrastructure is required to run CMA?
CMA is a complex architecture that requires multiple components. You need a vector database (e.g., Pinecone, Weaviate) to store episodic memory, a graph database (e.g., Neo4j) for semantic memory, and a strong orchestration framework (e.g., LangGraph) to control the processes. Naturally, access to an advanced LLM (e.g., GPT-4o, Claude 3.5 Sonnet) is also required for reasoning and generation tasks.
How can I integrate CMA into my existing RAG AI chatbot project?
Integration can happen gradually. As a first step, it is worth developing episodic memory by introducing time-weighted vector search. The next step is processing documents into a knowledge graph (introducing GraphRAG), and finally separating tools and APIs into a dedicated procedural layer. It is recommended to use frameworks like LangChain or LlamaIndex, which already have built-in modules for these tasks.
What future developments can be expected in CMA?
In the future, CMA systems are expected to become fully multimodal, capable of integrating images, videos, and audio into the memory layers. Additionally, predictive capabilities are expected to develop, where AI proactively offers solutions based on procedural and episodic patterns. Through federated learning, memory systems will be able to securely share knowledge with each other without raw data ever leaving the company.


