TL;DR: RAG AI Chatbotok a LinkedIn Cognitive Memory Agent (CMA) segítségével
A mesterséges intelligencia rohamos fejlődése ellenére a vállalati szektor sokáig küzdött egy alapvető problémával: az AI modellek „amnéziájával”. A LinkedIn legújabb áttörése, a Cognitive Memory Agent (CMA) pontosan erre a kihívásra ad választ.
A napokban bemutatott kutatási anyag rávilágít arra, hogy a puszta kontextusablak-növelés nem elegendő a valódi intelligencia eléréséhez. A CMA egy olyan strukturált memóriarendszert javasol, amely képes megkülönböztetni a múltbeli eseményeket, a ténybeli tudást és a cselekvési mintákat.
Ez a technológiai ugrás nem csupán a RAG AI chatbotok pontosságát növeli, hanem teljesen új szintre emeli a felhasználói élményt. A rendszer képes emlékezni a hetekkel ezelőtti preferenciákra, miközben másodpercek alatt dolgoz fel hatalmas vállalati adatbázisokat.

Mi a RAG AI Chatbot, és miért van szükség rá?
A Retrieval-Augmented Generation (RAG) technológia az elmúlt évek legfontosabb innovációja a nagy nyelvi modellek (LLM) gyakorlati alkalmazásában. De mi is ez pontosan?
A hagyományos LLM-ek (mint a ChatGPT alapmodelljei) egy statikus tudásbázissal rendelkeznek, amely a tanításuk pillanatában „befagyott”. Nem ismerik a cége belső szabályzatait, az aktuális raktárkészletet vagy a legfrissebb iparági híreket.
Ezzel szemben egy AI Chatbot (RAG) képes valós időben külső adatbázisokból információt kinyerni, és azt a válaszgenerálás során felhasználni. Ez a folyamat két fő lépésből áll: a visszakeresésből (Retrieval) és a generálásból (Generation).
Definíció: RAG (Retrieval-Augmented Generation)
Olyan AI architektúra, amely a nagy nyelvi modellek (LLM) generatív képességeit ötvözi egy dedikált információ-visszakereső rendszerrel. Ahelyett, hogy a modell a saját (esetleg elavult vagy pontatlan) belső súlyaira hagyatkozna, a RAG először releváns dokumentumokat keres egy külső adatbázisban (pl. vektoradatbázisban), majd ezeket az információkat kontextusként átadja az LLM-nek a pontos, tényalapú válasz megfogalmazásához.
A RAG rendszerek bevezetése drasztikusan csökkenti az úgynevezett „hallucinációkat” – azokat az eseteket, amikor az AI magabiztosan állít valótlanságokat. Mivel a válaszok konkrét, visszakeresett dokumentumokon alapulnak, a források mindig ellenőrizhetők.
Azonban a vállalati környezetben a puszta ténykeresés gyakran nem elegendő. A felhasználók elvárják, hogy a chatbot emlékezzen a korábbi interakciókra, értse a komplex összefüggéseket, és képes legyen több lépésből álló feladatokat végrehajtani.
Itt ütközünk bele a hagyományos RAG rendszerek korlátaiba, amelyek többnyire csak a legutóbbi néhány üzenetet képesek a memóriájukban tartani. A vállalati tudáskezelés forradalma megköveteli a memóriakezelés újragondolását.

A RAG AI Chatbot kihívásai: A rövid távú memória problémája
Bármilyen lenyűgözőek is a mai RAG rendszerek, egy komoly architekturális akadállyal küzdenek: a kontextusablak korlátaival. Bár a legújabb modellek (mint a Gemini 1.5 Pro vagy a Claude 3 Opus) hatalmas, akár több millió tokenes kontextusablakkal rendelkeznek, ez nem oldja meg a memóriaproblémát.
Miért? Először is, a hatalmas kontextusablakok feldolgozása rendkívül költséges és lassú. Minden egyes üzenetváltásnál a teljes korábbi beszélgetést és a visszakeresett dokumentumokat újra át kell küldeni a modellnek.
Másodszor, a kutatások (például a híres „Lost in the Middle” tanulmány) kimutatták, hogy az LLM-ek hajlamosak elfelejteni vagy figyelmen kívül hagyni a hosszú kontextus közepén elhelyezkedő információkat. Csak az elejére és a végére fókuszálnak.
"A mesterséges intelligencia valódi áttörését nem a modellek méretének növelése, hanem a memóriakezelés intelligenssé tétele fogja elhozni." – részlet a LinkedIn CMA kutatásából.
A hagyományos RAG rendszerek vektoradatbázisokat használnak a szemantikai kereséshez. Ez kiválóan működik, ha a kérdés egy konkrét dokumentumra vonatkozik (pl. „Mi a cég szabadságolási irányelve?”).
Azonban csődöt mond, ha a kérdés implicit kontextust igényel (pl. „A múlt héten említett projekt alapján, mikor kell leadnom a jelentést?”). A vektoradatbázis nem érti az időbeliséget, sem a felhasználó és a projekt közötti komplex kapcsolatot.
Ez az úgynevezett architekturális amnézia, amely frusztráló felhasználói élményhez és pontatlan válaszokhoz vezet. A LinkedIn mérnökei felismerték, hogy a megoldást az emberi agy működésének modellezése jelentheti.
Bemutatjuk a LinkedIn Cognitive Memory Agent (CMA) architektúráját
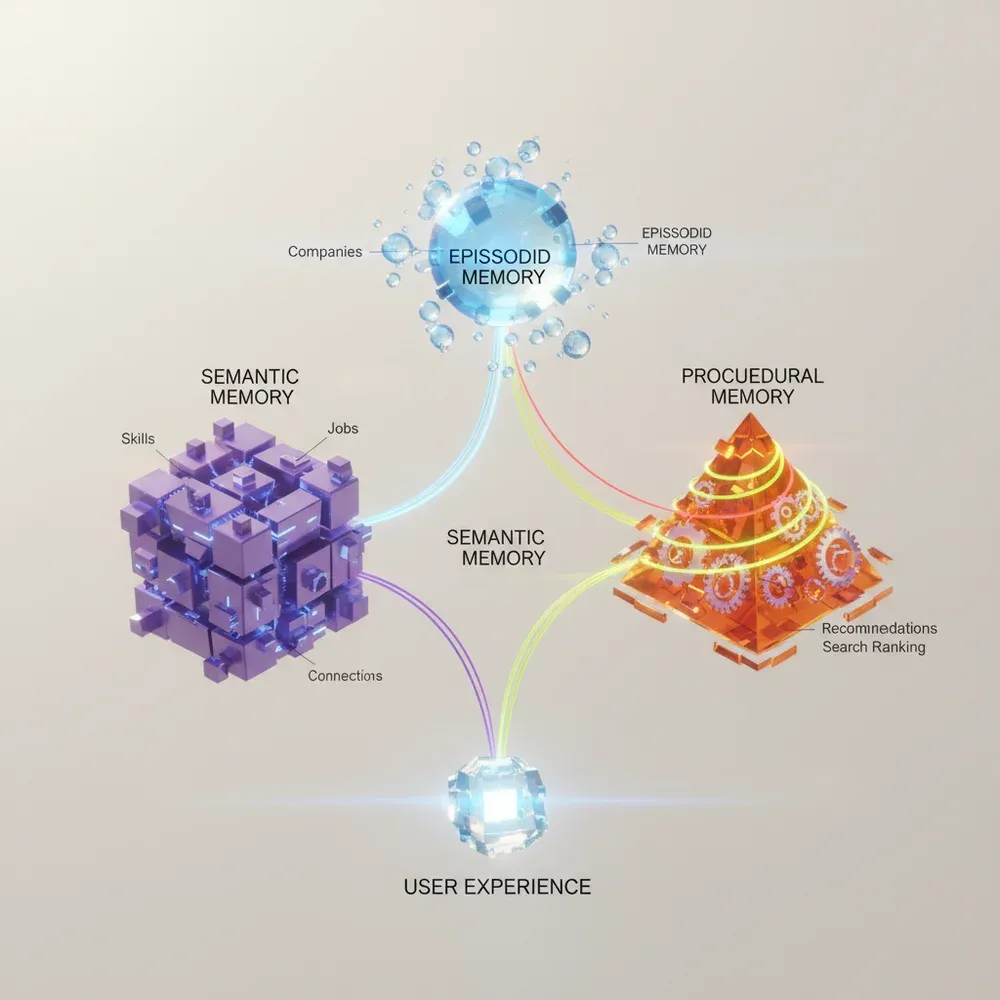
A LinkedIn által kifejlesztett Cognitive Memory Agent (CMA) egy paradigmaváltó megközelítés. Ahelyett, hogy egyetlen hatalmas adatbázisba ömlesztené az összes információt, a CMA a memóriát három, jól elkülöníthető, mégis együttműködő rétegre bontja.
Ezt a modellt a kognitív pszichológia ihlette, amely az emberi memóriát is hasonló kategóriákba sorolja. A CMA célja, hogy az AI ügynökök ne csak „olvassanak” az adatokból, hanem valóban „emlékezzenek” a kontextusra és a folyamatokra.
A LinkedIn modell bizonyítja, hogy a strukturált memóriakezelés elengedhetetlen a skálázható és megbízható vállalati AI rendszerek építéséhez.
A CMA Háromrétegű Architektúrája
- Episodic Memory (Epizodikus Memória): A múltbeli események, interakciók és beszélgetések naplója. Időbélyeggel ellátott, szekvenciális adatokat tárol.
- Semantic Memory (Szemantikus Memória): A ténybeli tudás, fogalmak és entitások közötti kapcsolatok hálózata. Általában tudásgráfként (Knowledge Graph) van implementálva.
- Procedural Memory (Procedurális Memória): A cselekvések, munkafolyamatok és API-hívások szabályrendszere. Ez mondja meg az ügynöknek, hogy hogyan hajtson végre egy feladatot.
Amikor egy felhasználó kérdést tesz fel, a CMA egy komplex orchestrációs rétegen (például LangGraph vagy AutoGen) keresztül dönti el, hogy melyik memóriarétegből kell információt lekérnie.
Gyakran mindhárom réteg együttes használatára van szükség. Például, ha a felhasználó azt kéri: „Küldd el a tegnapi megbeszélés összefoglalóját a marketing csapatnak”, a rendszer az epizodikus memóriából kikeresi a tegnapi megbeszélést, a szemantikus memóriából azonosítja a marketing csapat tagjait, a procedurális memóriából pedig lekéri az e-mail küldés folyamatát.
Ez a szinergia teszi a CMA-t a hagyományos RAG rendszereknél nagyságrendekkel intelligensebbé és hatékonyabbá.
Az Episodic Memory szerepe a RAG AI Chatbotoknál
Az epizodikus memória az AI ügynök személyes naplója. Ez a réteg felelős a felhasználóval folytatott korábbi interakciók, a kontextus és az időbeli események rögzítéséért. Nélküle a chatbot minden egyes üzenetnél tiszta lappal indulna.
A hagyományos rendszerekben ezt gyakran egy egyszerű memóriapufferrel oldják meg, amely az utolsó 5-10 üzenetet tartja meg. A CMA epizodikus memóriája azonban sokkal kifinomultabb. Nemcsak a nyers szöveget tárolja, hanem a beszélgetésből kinyert szándékokat (intents), érzelmeket és kulcsfontosságú eseményeket is.
Technikailag ez gyakran egy idősoros adatbázis és egy vektoradatbázis kombinációjával valósul meg. Minden bejegyzés kap egy időbélyeget és egy beágyazást (embedding), ami lehetővé teszi a gyors szemantikai és időalapú keresést.
- Állapottartó (Stateful) beszélgetések: A felhasználó visszatérhet egy hetekkel ezelőtt megkezdett témához, és az AI azonnal felveszi a fonalat.
- Kontextuális felbontás: Ha a felhasználó azt mondja, "alkalmazd ezt a korábbi projektre", az epizodikus memória azonosítja, melyik projektről van szó.
- Idő-súlyozott visszakeresés: A rendszer a frissebb információkat relevánsabbnak tekintheti, de képes a régebbi, kritikus fontosságú adatok felszínre hozására is.
Képzeljünk el egy ügyfélszolgálati szituációt. Egy ügyfél panaszt tesz egy termékre. Két héttel később újra ír, hogy "Még mindig nem kaptam meg a cseredarabot".
Egy hagyományos chatbot nem értené, miről van szó. A CMA epizodikus memóriája viszont azonnal összekapcsolja az új üzenetet a két héttel ezelőtti panasztétellel, lekéri a jegy (ticket) számát, és releváns választ ad. Ez az alapja a professzionális AI Telefonos Ügyfélszolgálatnak is.
A Semantic Memory működése és előnyei
Míg az epizodikus memória a "mikor" és "mi történt" kérdésekre válaszol, a szemantikus memória a "mi ez" és "hogyan kapcsolódik" kérdésekre fókuszál. Ez a réteg a rendszer objektív, ténybeli tudásbázisa.
A LinkedIn CMA architektúrájában a szemantikus memóriát jellemzően Tudásgráfok (Knowledge Graphs) segítségével implementálják. A vektoradatbázisokkal ellentétben, amelyek a szövegek statisztikai hasonlóságát mérik, a tudásgráfok explicit kapcsolatokat építenek ki az entitások között.
Ezek a kapcsolatok úgynevezett triplet (hármas) formátumban tárolódnak: Alany - Állítmány - Tárgy (pl. "Kovács János" - "dolgozik" - "Marketing Osztály"). Ez a struktúra lehetővé teszi a komplex, logikai következtetéseket igénylő lekérdezéseket.
"A GraphRAG (Graph Retrieval-Augmented Generation) integrálása a szemantikus memóriába drasztikusan, akár 70%-kal is csökkentheti a ténybeli tévedések (hallucinációk) arányát a komplex vállalati lekérdezéseknél."
Amikor egy RAG AI chatbot a szemantikus memóriát használja, képes átlátni a vállalati silókat. Ha felteszik a kérdést: "Mely projekteken dolgoznak jelenleg azok a fejlesztők, akik értenek a Reacthoz?", a rendszer a gráfon végighaladva (graph traversal) pontos választ ad.
A szemantikus memória folyamatosan frissül. Az adatfeldolgozó AI-ügynökök a háttérben olvassák a bejövő dokumentumokat, kinyerik belőlük az új entitásokat és kapcsolatokat, majd beillesztik azokat a tudásgráfba.
Ez a dinamikus tudásépítés biztosítja, hogy a chatbot mindig a legfrissebb és legpontosabb vállalati információk birtokában legyen, kiküszöbölve a statikus RAG rendszerek elavulási problémáit.

Procedural Memory: A RAG AI Chatbotok trükkjei
A harmadik, és talán legizgalmasabb réteg a procedurális memória. Ez a réteg teszi képessé a chatbotot arra, hogy passzív információszolgáltatóból aktív cselekvővé váljon. Ez tárolja a "hogyan"-t.
A procedurális memória lényegében egy eszköztár (tool repository) és a hozzájuk tartozó használati utasítások gyűjteménye. Tartalmazza az API hívások szintaktikáját, a munkafolyamatok (workflows) lépéseit, és a hibakezelési protokollokat.
Amikor a felhasználó egy cselekvést kér (pl. "Hozz létre egy új Jira ticketet a belépési hibáról"), a CMA a procedurális memóriához fordul. Lekéri a Jira API hitelesítési módját, a kötelező mezők listáját, és a JSON payload struktúráját.
A Procedurális Memória Előnyei
Lehetővé teszi az egyedi automatizálás integrálását közvetlenül a chat felületbe. Az AI ügynök képes önállóan navigálni a vállalati szoftverek (ERP, CRM, HR rendszerek) között, adatokat módosítani, e-maileket küldeni, vagy akár kódokat futtatni, mindezt szigorú jogosultságkezelés mellett.
A LinkedIn kutatása rávilágít, hogy a procedurális memória elválasztása a nyelvi modelltől növeli a rendszer stabilitását. Ahelyett, hogy az LLM-nek minden API dokumentációt a kontextusablakában kellene tartania, csak a releváns "receptet" kapja meg a végrehajtás pillanatában.
Ez a réteg teszi lehetővé a komplex, több ügynökös (multi-agent) rendszerek orchestrációját is. A procedurális memória definiálja, hogy melyik specializált ügynök (pl. kódoló ügynök, adatelemző ügynök) mikor és hogyan lépjen be a folyamatba.
A RAG chatbot evolúciója egyértelműen az autonóm, cselekvőképes ügynökök felé mutat, amelyek alapja a robusztus procedurális memória.
A CMA hatása a RAG AI Chatbotok teljesítményére
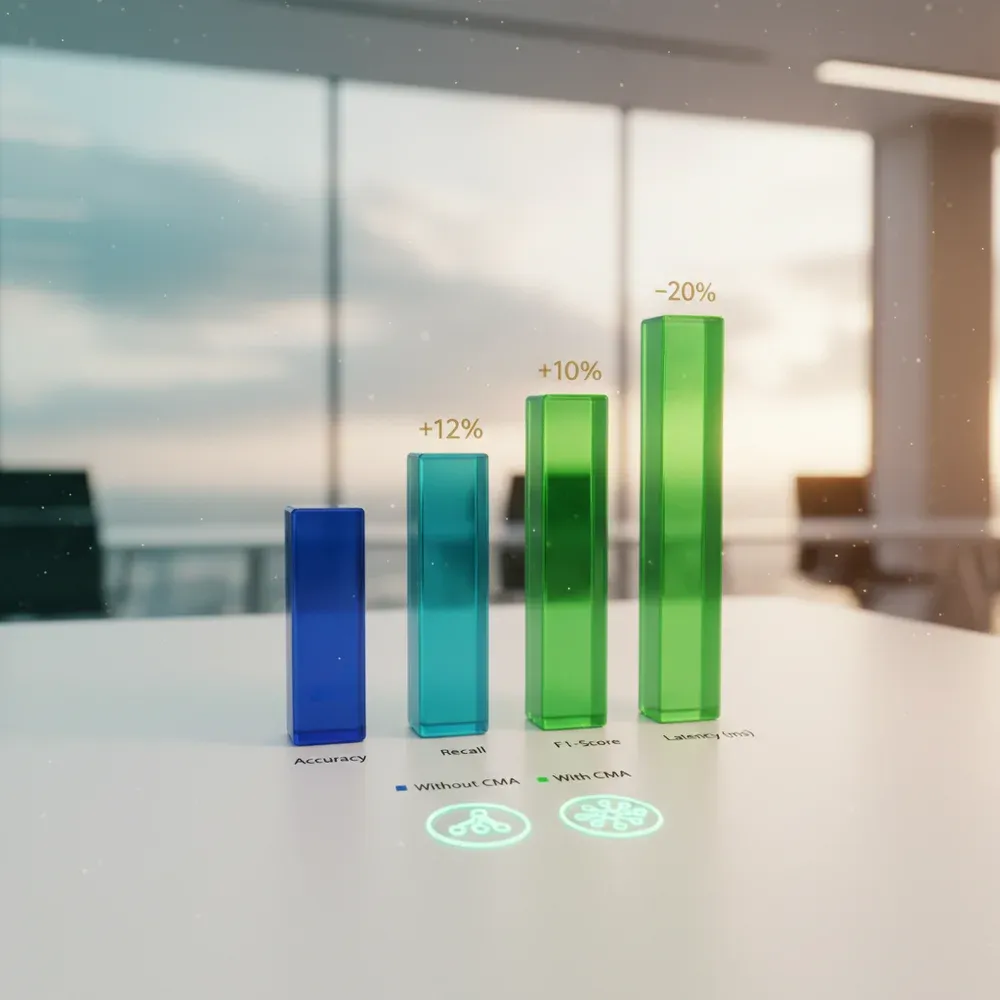
A LinkedIn CMA architektúrájának bevezetése nem csupán elméleti érdekesség; drámai, mérhető javulást hoz a RAG rendszerek teljesítményében. A kutatási eredmények és az iparági benchmarkok egyértelműen bizonyítják a technológia fölényét.
A legfontosabb mérőszám a hallucinációk csökkenése. Mivel a CMA a szemantikus memórián (tudásgráfon) keresztül validálja a tényeket, és az epizodikus memóriából nyeri a pontos kontextust, a modell sokkal ritkábban talál ki fals információkat.
A benchmarkok szerint a komplex, több ugrásos (multi-hop) lekérdezéseknél a CMA-alapú rendszerek pontossága (accuracy) akár 40-50%-kal is meghaladhatja a hagyományos, csak vektoros RAG rendszerekét.
- Megnövelt Recall (Visszahívás): A rendszer sokkal nagyobb eséllyel találja meg a releváns információt a hatalmas adatbázisokban a gráf-alapú keresés révén.
- Gyorsabb válaszidő: Bár az architektúra komplexebb, a célzott memóriakeresés miatt kevesebb felesleges adatot kell az LLM-nek feldolgoznia, ami csökkenti a generálási időt (latency).
- Költséghatékonyság: A kisebb, optimalizált kontextusablakok használata jelentősen csökkenti az API hívások költségeit (token cost).
Egy másik kritikus teljesítménymutató a felhasználói elégedettség. A stateful, emlékező chatbotok sokkal természetesebb és frusztrációmentesebb élményt nyújtanak.
A felhasználóknak nem kell újra és újra elmagyarázniuk a problémájukat, ami növeli a rendszer elfogadottságát és a napi aktív használatot (DAU) a vállalati környezetben.
Hogyan integrálhatod a CMA-t a RAG AI Chatbot projektjeidbe?
A CMA architektúra implementálása komoly mérnöki feladat, de a modern AI keretrendszerek (mint a LangChain, LlamaIndex vagy a LangGraph) jelentősen megkönnyítik a folyamatot. Lássuk a lépéseket!
1. Az Infrastruktúra Kialakítása: Szükséged lesz egy vektoradatbázisra (pl. Pinecone, Weaviate, Qdrant) az epizodikus memória beágyazásainak tárolására. A szemantikus memóriához egy gráfadatbázis (pl. Neo4j) az ideális választás.
2. Az Epizodikus Memória Implementálása: Minden felhasználói interakciót el kell menteni az adatbázisba egy időbélyeggel, a felhasználó azonosítójával és a szöveg vektoros reprezentációjával. A visszakeresésnél kombinálni kell a szemantikai hasonlóságot az időbeli relevanciával (time-weighted vector search).
Tipp a Fejlesztőknek: Orchestráció
Használj állapotalapú orchestrátort, mint a LangGraph. Hozz létre különálló csomópontokat (nodes) a memóriarétegek lekérdezésére. Egy központi "Routing Agent" döntheti el a felhasználó kérdése alapján, hogy melyik memóriaréteget kell aktiválni, így optimalizálva a teljesítményt és a tokenhasználatot.
3. A Szemantikus Memória (Tudásgráf) Építése: Ez a legösszetettebb lépés. Az adatfeldolgozó AI-ügynökök segítségével fel kell dolgozni a vállalati dokumentumokat, kinyerni az entitásokat (NER - Named Entity Recognition) és a kapcsolatokat, majd ezeket betölteni a Neo4j-be.
4. A Procedurális Memória Definiálása: Hozz létre egy regisztert az elérhető eszközökről (Tools). Definiáld az API sémákat (OpenAPI specifikációk) és a végrehajtási logikát. Az LLM-nek csak a funkciók leírását (Function Calling) add át, a tényleges végrehajtást egy biztonságos, izolált környezetben végezd.
Az AiSolve szakértő csapata pontosan ilyen komplex, CMA-alapú architektúrákat épít. Ha szeretnéd elkerülni a buktatókat, érdemes profikra bízni a tervezést és a kivitelezést.
E-E-A-T a RAG AI Chatbotoknál: Mi a megbízhatóság kulcsa?
A vállalati AI rendszereknél a technológiai bravúr önmagában nem elég; a rendszernek megbízhatónak kell lennie. A Google E-E-A-T (Tapasztalat, Szakértelem, Tekintély, Megbízhatóság) elvei kiválóan alkalmazhatók a RAG AI chatbotok minőségbiztosítására is.
A Megbízhatóság (Trust) a legfontosabb pillér. A CMA architektúra transzparenciát biztosít. Amikor a chatbot válaszol, pontosan meg tudja mutatni, hogy az információt a szemantikus memória melyik gráf-csomópontjából, vagy az epizodikus memória melyik korábbi beszélgetéséből vette.
Ez a fajta magyarázhatóság (Explainable AI - XAI) kritikus a pénzügyi, jogi vagy egészségügyi szektorokban, ahol egy hibás AI válasz súlyos következményekkel járhat.
"Az adatminőség határozza meg az AI minőségét. A legfejlettebb CMA architektúra is csak annyira jó, amennyire a szemantikus memóriájába táplált adatok tiszták és strukturáltak."
A Szakértelem (Expertise) a procedurális memóriában rejlik. A chatbotnak nemcsak tudnia kell a választ, hanem képesnek kell lennie a szakszerű végrehajtásra is, betartva a vállalati protokollokat és a biztonsági előírásokat.
A robusztus jogosultságkezelés (RBAC) integrálása a memóriarétegekbe biztosítja, hogy a felhasználók csak azokhoz az információkhoz és funkciókhoz férjenek hozzá, amelyekre engedélyük van. Ez az alapja a biztonságos vállalati AI bevezetésnek.
A jövő RAG AI Chatbotjai: A CMA evolúciója
A LinkedIn CMA architektúrája csak a kezdet. Ahogy a technológia fejlődik, a memóriarétegek egyre kifinomultabbá és integráltabbá válnak. A jövő RAG rendszerei teljesen multimodálisak lesznek.
Képzeljük el, hogy az epizodikus memória nemcsak szöveges üzeneteket, hanem a felhasználó által feltöltött képeket, hanganyagokat, vagy akár a képernyőmegosztás videóit is képes feldolgozni és tárolni. A rendszer emlékezni fog arra, hogy "a múlt heti videóhívásban mutatott diagram alapján...".
A szemantikus memória egyre inkább globális, megosztott tudásgráfokká fog fejlődni, ahol a vállalat különböző osztályainak AI ügynökei közösen építik és frissítik a cég kollektív tudásbázisát valós időben.
- Prediktív Memória: Az AI nemcsak emlékezni fog, hanem a procedurális és epizodikus minták alapján előre látja a felhasználó igényeit, és proaktívan cselekszik.
- Federált Tanulás (Federated Learning): A memóriarendszerek képesek lesznek tanulni egymástól anélkül, hogy a szenzitív nyers adatokat megosztanák, növelve az adatvédelmet.
- Hardware-szintű optimalizáció: Új típusú chipek (pl. LPU-k) jelennek meg, amelyek kifejezetten a gráf-alapú memóriakeresés és a RAG folyamatok gyorsítására lettek tervezve.
Azok a vállalatok, amelyek időben felismerik a fejlett memóriakezelés jelentőségét, és bevezetik a CMA-hoz hasonló architektúrákat, behozhatatlan versenyelőnyre tesznek szert a piacon.
Készen állsz egy forradalmian új RAG AI chatbotra?
A hagyományos, feledékeny chatbotok ideje lejárt. Ha szeretnéd, hogy vállalatod egy valóban intelligens, a kontextust értő és a folyamatokat automatizáló AI asszisztenssel lépjen a következő szintre, a CMA architektúra a megoldás.
Az AiSolve csapata élen jár a legmodernebb RAG rendszerek és AI ügynökök fejlesztésében. Nem dobozos megoldásokat kínálunk, hanem a te vállalkozásod egyedi igényeire szabott, biztonságos és skálázható architektúrákat építünk.
Lépj szintet a vállalati hatékonyságban! Ismerd meg AI Chatbot (RAG) szolgáltatásunkat, vagy kérj ingyenes konzultációt, és tervezzük meg együtt a jövőálló AI stratégiádat!
Gyakran Ismételt Kérdések (GYIK)
Mi a legfőbb különbség a RAG AI chatbotok és a hagyományos chatbotok között?
A hagyományos chatbotok előre megírt szabályok (döntési fák) alapján működnek, vagy egy statikus, betanított nyelvi modellt használnak, amely nem ismeri a legfrissebb vagy belső vállalati adatokat. Ezzel szemben a RAG (Retrieval-Augmented Generation) AI chatbotok képesek valós időben keresni a vállalat saját dokumentumaiban, adatbázisaiban, és ezeket az információkat felhasználva pontos, tényalapú és aktuális válaszokat generálni, jelentősen csökkentve a hallucinációk esélyét.
Hogyan javítja a CMA a RAG AI chatbotok pontosságát?
A CMA (Cognitive Memory Agent) a memóriát három rétegre bontja: epizodikus (múltbeli interakciók), szemantikus (ténybeli tudásgráf) és procedurális (cselekvési szabályok). Ez a strukturált megközelítés lehetővé teszi a rendszer számára, hogy pontosan értse a kontextust, emlékezzen a korábbi beszélgetésekre, és logikai összefüggéseket találjon az adatok között. Így a modell nem veszik el a hatalmas kontextusablakokban, és sokkal precízebb, relevánsabb válaszokat ad.
Milyen a CMA architektúrájának előnyei a hagyományos RAG rendszerekhez képest?
A hagyományos RAG általában csak vektoros keresést használ, ami jó a dokumentumok megtalálására, de gyenge a komplex összefüggések és az időbeliség megértésében. A CMA a tudásgráfok (szemantikus memória) révén érti az entitások közötti kapcsolatokat, az epizodikus memória révén pedig állapottartó (stateful) beszélgetéseket tesz lehetővé. Emellett a procedurális memória révén képes autonóm feladatvégrehajtásra, amit a sima RAG nem tud.
Milyen infrastruktúrára van szükség a CMA futtatásához?
A CMA egy összetett architektúra, amely több komponenst igényel. Szükség van egy vektoradatbázisra (pl. Pinecone, Weaviate) az epizodikus memória tárolásához, egy gráfadatbázisra (pl. Neo4j) a szemantikus memóriához, valamint egy erős orchestrációs keretrendszerre (pl. LangGraph) a folyamatok irányításához. Természetesen szükség van hozzáférésre egy fejlett LLM-hez (pl. GPT-4o, Claude 3.5 Sonnet) is az érvelési és generálási feladatokhoz.
Hogyan integrálhatom a CMA-t a meglévő RAG AI chatbot projektembe?
Az integráció fokozatosan is történhet. Első lépésként érdemes az epizodikus memóriát fejleszteni egy idő-súlyozott vektoros keresés bevezetésével. A következő lépés a dokumentumok feldolgozása egy tudásgráfba (GraphRAG bevezetése), majd végül az eszközök és API-k leválasztása egy dedikált procedurális rétegbe. Javasolt olyan keretrendszerek használata, mint a LangChain vagy a LlamaIndex, amelyek már rendelkeznek beépített modulokkal ezekhez a feladatokhoz.
Milyen jövőbeli fejlesztések várhatók a CMA-ban?
A jövőben a CMA rendszerek várhatóan teljesen multimodálissá válnak, képesek lesznek képeket, videókat és hanganyagokat is integrálni a memóriarétegekbe. Emellett a prediktív képességek fejlődése várható, ahol az AI proaktívan kínál megoldásokat a procedurális és epizodikus minták alapján. A federált tanulás révén pedig a memóriarendszerek biztonságosan oszthatnak meg tudást egymás között, anélkül, hogy a nyers adatok elhagynák a vállalatot.
Készen állsz a saját weboldaladra?
Ingyenes konzultáció során átbeszéljük, hogyan segíthetünk vállalkozásodnak növekedni egy modern, gyors és konverzióoptimalizált weboldallal. 14 nap alatt kész, 0 Ft induló költséggel.





