

| Terület | Kulcsfontosságú Megállapítás |
|---|---|
| Teljesítmény | Az eszközön futó következtetés kiküszöböli a hálózati késleltetést, lehetővé téve az 50 ms alatti válaszidőt az AI feladatoknál, ami kritikus a valós idejű alkalmazások számára. |
| Adatvédelem és Biztonság | Az adatok helyi feldolgozásával az érzékeny felhasználói információk soha nem hagyják el az eszközt, így alapértelmezetté válik a teljes adatvédelem és biztonság. |
| Technológia | A siker az energiahatékony kerneleken és a mobil hardverre optimalizált natív futtatókörnyezeteken múlik, hogy magas teljesítményt nyújtsanak az akkumulátor lemerítése nélkül. |
| Piaci Hatás | Ez a technológia az értéket a központosított felhőszolgáltatóktól a peremeszközök hardveres és szoftveres optimalizációi felé tolja, új lehetőségeket nyitva a mobil, viselhető és IoT eszközök számára. |
| Hozzáférhetőség | A helyi LLM-ek lehetővé teszik az erőteljes AI funkciók működését állandó internetkapcsolat nélkül, drasztikusan javítva a megbízhatóságot és a hozzáférhetőséget alacsony lefedettségű területeken. |
Az elmúlt néhány évben a Nagy Nyelvi Modellek (LLM) képességei üstökösként emelkedtek, átalakítva mindent az ügyfélszolgálattól a tartalomkészítésig. Ez a forradalom azonban szinte teljes mértékben egy központosított, felhőalapú architektúrától függött. Minden lekérdezés, minden parancs, minden adatdarab hatalmas szerverfarmokra kerül feldolgozásra, ami eredendően szűk keresztmetszeteket teremt a sebességben és jelentős aggályokat vet fel az adatvédelemmel kapcsolatban. Felhasználóként hozzászoktunk a csekély – és néha jelentős – késleltetéshez egy kérdés feltevése és a válasz megérkezése között. Iparági elemzések szerint már egy 100 ezredmásodperces késleltetés is negatívan befolyásolhatja a felhasználói elköteleződést, pedig sok felhőalapú AI interakció ennél jóval tovább tart. Ez a modell, bár erőteljes, kezdi megmutatni korlátait egy olyan világban, amely azonnali, privát és megbízható intelligenciát követel. A jövő nem csupán arról szól, hogy okosabbá tegyük az MI-t; arról is szól, hogy gyorsabbá, biztonságosabbá és hozzáférhetőbbé tegyük azzal, hogy kivonjuk a felhőből és közvetlenül a kezünkbe adjuk.
Egy új innovációs hullám van felemelkedőben, hogy megfeleljen ennek a kihívásnak, amelyet olyan technológiák vezetnek, amelyek erőteljes AI modelleket képesek közvetlenül a felhasználói eszközökön futtatni. A Y Combinator által támogatott Cactus startup áll ennek a mozgalomnak az élén a Cactus v1 keretrendszerével, amely gyakorlatilag nulla késleltetésű és abszolút adatvédelmet biztosító eszközön futó LLM következtetést ígér. Azáltal, hogy a számítási terhelést a távoli szerverekről a mindennap használt eszközeinkre – okostelefonokra, viselhető eszközökre és más alacsony fogyasztású hardverekre – helyezi át, ez a megközelítés alapvetően újraértelmezi a felhasználó-MI kapcsolatot. Ez a cikk az eszközön történő következtetés felé történő technológiai elmozdulást, annak a késleltetésre és adatvédelemre gyakorolt mélyreható hatásait vizsgálja, és azt, hogy a Cactus V1-hez hasonló keretrendszerek hogyan építik fel az intelligens alkalmazások következő generációját. Lebontjuk az alapvető komponenseket, összehasonlítjuk az eszközön futó modellt a felhőalapú elődjével, és megvizsgáljuk azt a hatalmas potenciált, amelyet egy valóban személyes MI-élmény számára felszabadít.
A Felhőfüggőség Dilemmája: Késleltetés és Adatvédelmi Szűk Keresztmetszetek
A nagyméretű AI telepítésének hagyományos bölcsessége egyszerű volt: használd a felhő hatalmas erejét. Ez a modell gyors fejlődést tett lehetővé, lehetővé téve a fejlesztők számára, hogy több százmilliárd paraméteres modelleket használjanak anélkül, hogy aggódniuk kellene a végfelhasználó hardverkorlátai miatt. Ez a függőség azonban olyan kompromisszumot teremtett, amely egyre nyilvánvalóbbá válik. Az első nagy szűk keresztmetszet a késleltetés. Minden interakció egy felhőalapú LLM-mel egy oda-vissza utazás. A felhasználó bevitele az eszközéről az interneten keresztül egy adatközpontba utazik, a modell feldolgozza, és a válasz visszautazik. Ez az út, amely a hálózati torlódásoknak, a szerver terhelésének és a fizikai távolságnak van kitéve, érezhető késést okoz. Bár egyes feladatoknál ez elfogadható, a valós idejű interakciót igénylő alkalmazásoknál, mint például a dinamikus hangasszisztensek, a kiterjesztett valóság rétegei vagy a menet közbeni nyelvfordítás, ez elfogadhatatlan.
A második, és vitathatatlanul kritikusabb szűk keresztmetszet az adatvédelem. A felhőközpontú modellben a felhasználói adatok olyan árucikkek, amelyeket egy harmadik félnek kell továbbítania és feldolgoznia. Minden személyes jegyzet, amit egy MI-nek diktálnak, minden érzékeny üzleti dokumentum, amit összefoglalnak, minden privát egészségügyi kérdés, amit feltesznek – mindez kikerül a felhasználó ellenőrzése alól. Bár a vállalatok biztonsági intézkedéseket vezetnek be, az adatok továbbra भी sebezhetőek a jogsértésekkel, a megfigyeléssel és az adatfelhasználásra vonatkozó vállalati irányelvek változásaival szemben. Ez a paradigma nehéz választás elé állítja a felhasználókat: feláldozzák a magánéletüket a funkcionalitásért. A vállalatok számára ez a kockázat megsokszorozódik, mivel a tulajdonosi adatok külső szerverekre történő továbbítása sértheti a megfelelési előírásokat és értékes szellemi tulajdont tehet ki. A felhőalapú AI alapvető architektúrája központi meghibásodási pontot teremt mind a biztonság, mind a felhasználói bizalom szempontjából, egy olyan sebezhetőséget, amelyet az eszközön futó modell teljes mértékben kiküszöböl.
Az Eszközön Futtatott Következtetés Bemutatása: Egy Paradigmaváltás
Az eszközön – vagy peremhálózaton (edge) – történő következtetés a felhő-első AI modell alapvető megfordítását jelenti. Ahelyett, hogy az adatokat egy távoli agyhoz küldenénk, az agyat közvetlenül az eszközre hozzuk. Ez egy kicsinyített, mégis erőteljes LLM verzió helyi futtatását jelenti az eszköz saját processzorán, legyen az egy okostelefon SoC-ja (System on a Chip), egy viselhető eszköz mikrokontrollere vagy egy IoT eszköz dedikált AI gyorsítója. Az alapelv az adatok lokalizálása: a teljes folyamat, a bemenettől a kimenetig, egy zárt körben zajlik a felhasználó hardverén. Semmit nem küldenek a felhőbe, hacsak a felhasználó kifejezetten nem engedélyezi más célokra, például biztonsági mentésekre.
Ez a váltás nem csupán egy architekturális preferencia; ez egy stratégiai lépés a felhőfüggőség eredendő hibáinak megoldására. A helyi számítással az eszközön futó AI teljesen kikerüli a hálózatot. Az internet opcionálissá válik, nem pedig az intelligencia előfeltételévé. Ez azonnal két átalakító előnyt nyit meg. Először is, páratlan teljesítményt nyújt az interaktív feladatokhoz, mivel a fénysebesség és a hálózati forgalom többé nem korlátozó tényezők. Másodszor, új mércét állít fel az adatvédelem terén, létrehozva egy "zéró tudású" környezetet, ahol az alkalmazásszolgáltatónak nem kell látnia, kezelnie vagy tárolnia a felhasználói adatokat a szolgáltatás nyújtásához. Ez a paradigmaváltás utat nyit egy ellenállóbb, személyesebb és megbízhatóbb AI alkalmazásosztály számára, amely bármikor, bárhol zökkenőmentesen működhet. Az ilyen reszponzív rendszereket implementálni kívánó vállalkozások felfedezhetik azokat az AI-alapú kommunikációs megoldásokat, amelyek kiaknázzák ezt az azonnali válaszképességet.
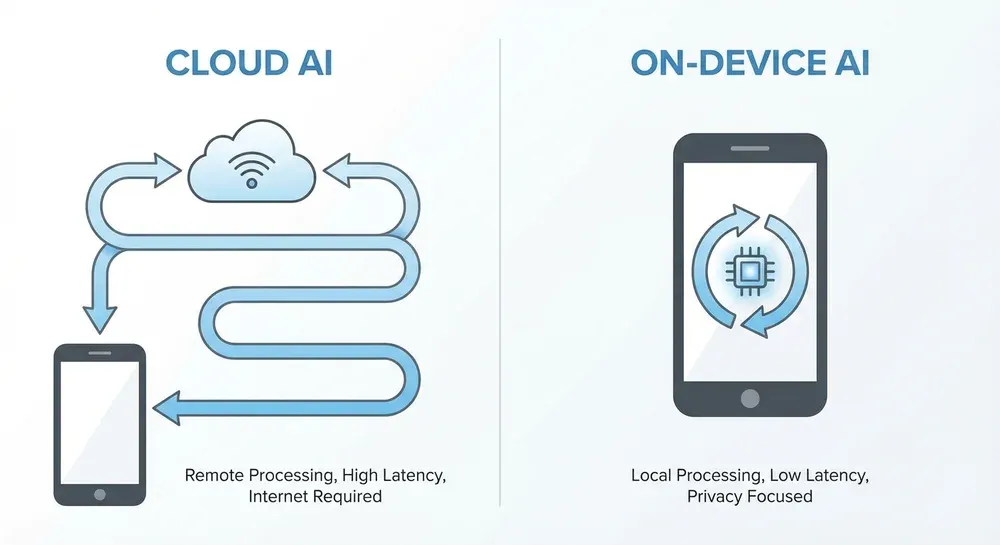
Ábra: A felhőalapú és az eszközön futó AI adatútvonalainak összehasonlítása, kiemelve a hálózati késleltetés kiküszöbölését az utóbbiban.
A Késleltetési Korlát: Miért Számítanak a Milliszekundumok?
Az ember-gép interakcióban a késleltetés a felhasználói élmény csendes gyilkosa. Az "azonnali" érzékelésünk hihetetlenül érzékeny; a másodperc töredékében mért késések egy alkalmazást lassúnak, nem reagálónak és nem intuitívnak éreztethetnek. Az AI esetében ez különösen igaz. Egy társalgási AI, amely egy teljes másodpercet vesz igénybe a válaszadáshoz, természetellenesnek hat, megtörve a párbeszéd folyamatát. Egy AR alkalmazás, amely lemarad a felhasználó fejmozgásától, mozgásbetegséget okoz. Ezt a problémát kezeli és oldja meg közvetlenül az eszközön futó következtetés.
A Cactus V1-hez hasonló keretrendszereket úgy tervezték, hogy megsemmisítsék a hálózati késleltetést. A vállalat "50 ms alatti időt az első tokenig" jelent, egy olyan metrikát, amely a modell válaszának legelső darabjának generálásához szükséges időt képviseli. Ez egy kulcsfontosságú mérőszám, mert a rendszer azonnali érzékelt reakcióképességét tükrözi. Ezt a sebességet csak az adatok felhőbe történő oda-vissza útjának kiküszöbölésével lehet elérni. A lekérdezések közvetlen eszközhardveren történő feldolgozásával az egyetlen késleltetés maga a számítás, amelyet nagymértékben lehet optimalizálni. Ez valóban valós idejűnek érződő interakciókhoz vezet, lehetővé téve egy új alkalmazásosztályt. Képzeljünk el AI-alapú videószűrőket, amelyek bonyolult effektusokat alkalmaznak késedelem nélkül, okos asszisztenseket, amelyek olyan gyorsan adnak választ, ahogy csak beszélni tudunk, vagy hozzáférhetőségi eszközöket, amelyek késedelem nélkül írják le a világot egy látássérült személynek. Ez nem csak egy mennyiségi javulás; ez egy minőségi ugrás, amely az MI-t a felhasználó saját gondolatainak természetes kiterjesztésének érezteti.
Alapértelmezett Adatvédelem: A Helyi LLM-ek Megsérthetetlen Erődje
Az állandó adatvédelmi incidensek és a digitális megfigyeléssel kapcsolatos növekvő aggodalmak korában az adatvédelem egy funkcióból alapvető felhasználói joggá vált. Az eszközön futó AI modell ennek az elvnek a figyelembevételével épül fel. Amikor egy LLM helyben működik, az érzékeny információk – személyes beszélgetések, pénzügyi adatok, egészségügyi nyilvántartások, védett üzleti dokumentumok – soha nem kell, hogy egy harmadik félre legyenek bízva. Biztonságosan elzárva maradnak a felhasználó eszközén belül, teljes mértékben az ő ellenőrzésük alatt. Ezt jelenti az "alapértelmezett adatvédelem". Ez nem egy beállítás, amit engedélyezni kell; ez a rendszer tervezésének velejárója.
Ennek mélyreható következményei vannak mind a fogyasztók, mind a vállalatok számára. Az egyéni felhasználók számára ez azt jelenti, hogy szabadon használhatják az MI-t rendkívül személyes feladatokra anélkül, hogy félniük kellene az adatok bányászatától, eladásától vagy kiszivárogtatásától. Olyan szintű bizalmat teremt, amely a felhőalapú szolgáltatásokkal egyszerűen elérhetetlen. A vállalkozások számára az előnyök még jelentősebbek. Az olyan iparágak, mint az egészségügy, a pénzügy és a jog, szigorú adatvédelmi előírásokhoz (pl. GDPR, HIPAA) vannak kötve. Az eszközön futó következtetés lehetővé teszi számukra, hogy fejlett MI képességeket használjanak, miközben teljes mértékben megfelelnek az előírásoknak, mivel semmilyen védett adat nem hagyja el a telephelyet vagy a felhasználó eszközét. Védi a vállalati szellemi tulajdont is azáltal, hogy biztosítja, hogy a stratégiai tervek, a K+F adatok és a belső kommunikációk, amelyeket egy MI elemez, ne kerüljenek külső szerverekre. A felhasználó eszközének végső védővonallá tételével a helyi LLM-ek robusztus és megbízható biztonsági modellt hoznak létre. Ez az elv kiterjed arra is, hogyan építhetnek a vállalkozások biztonságosabb belső eszközöket, például egy fejlett RAG chatbotot belső tudásbázisokhoz, biztosítva, hogy a cégvédett adatok a vállalati tűzfalon belül maradjanak.

A Gépház: A Cactus V1 Technológiájának Boncolgatása
Nagy teljesítményű LLM következtetés biztosítása korlátozott erőforrású eszközökön komoly mérnöki kihívás. Finom egyensúlyt igényel a számítási teljesítmény, az energiafogyasztás és a modell mérete között. A Cactus V1 mögötti technológia kiemeli az ehhez az egyensúlyhoz szükséges kulcsfontosságú komponenseket: az energiahatékony kerneleket és a natív futtatókörnyezetet. Ezek az elemek kritikusak minden eszközön futó AI keretrendszer sikeréhez, és központi szerepet játszanak a hatékony adatfeldolgozásban mobil környezetben.
Energiahatékony Kernelek
A legalacsonyabb szinten a "kernel" ebben a kontextusban egy magasan optimalizált kódrészletet jelent, amely egy specifikus számítási feladatot hajt végre, például mátrixszorzást, ami a neurális hálózatok egyik alapvető művelete. Az "energiahatékony" azt jelenti, hogy ezeket a kerneleket az alapoktól úgy tervezték, hogy a lehető legkisebb energiafelhasználással működjenek. Ezt olyan kód írásával érik el, amely teljes mértékben kihasználja a mobil processzorok specifikus architektúráját (pl. az ARM NEON utasításait). Az általános, bárhol futó kód helyett ezek egyedi rutinok, amelyek a chip natív nyelvén beszélnek, csökkentve az elpazarolt ciklusokat és minimalizálva az akkumulátor lemerülését. Ez az optimalizálás teszi lehetővé, hogy egy eszköz bonyolult AI számításokat végezzen anélkül, hogy túlmelegedne vagy percek alatt lemerülne.
Natív Futtatókörnyezet
A "futtatókörnyezet" az a környezet, amely végrehajtja az AI modellt. A "natív" futtatókörnyezet olyan, amely nagyon közel helyezkedik el a hardverhez, absztrakciós vagy interpretációs rétegek nélkül, amelyek lelassíthatják a dolgokat. Gondoljunk rá úgy, mint a különbségre egy nagy teljesítményű versenyautó motorja és egy átlagos személyautó motorja között. A natív futtatókörnyezet célirányosan arra lett tervezve, hogy betöltse az optimalizált modellt, hatékonyan kezelje a memóriát, és a számításokat a lehető leggyorsabban továbbítsa az energiahatékony kerneleknek. A több platformon való működés révén a Cactus V1 futtatókörnyezete ezt a teljesítményt következetesen tudja nyújtani különböző operációs rendszereken (mint az iOS és Android) és hardvereken, egységes és kiszámítható fejlesztői élményt biztosítva. A specializált kernelek és a karcsú futtatókörnyezet ezen kombinációja az a technikai alap, amely lehetővé teszi az 50 ms alatti teljesítményt és a kifinomult eszközön futó AI-t gyakorlati valósággá teszi.
Eszközön Futó vs. Felhőalapú AI: Összehasonlító Elemzés
Az eszközön futó és a felhőalapú AI közötti választás nem arról szól, hogy melyik az egyetemesen "jobb", hanem arról, hogy melyik felel meg egy adott alkalmazás igényeinek. Mindkét modell eltérő előnyöket és kompromisszumokat kínál több kulcsfontosságú dimenzióban. Ezen különbségek megértése kulcsfontosságú a fejlesztők és a vállalkozások számára, akik hatékony és felhasználóközpontú AI megoldásokat kívánnak építeni. Sok vállalat számára az ideális megoldás gyakran egy hibrid megközelítést foglal magában, amely kihasználja az erőteljes, egyedi automatizálási megoldásokat, amelyek mindkét világ legjobbjait ötvözik.
Az alábbiakban egy részletes összehasonlítás található, amely kiemeli a két architektúra közötti elsődleges különbségeket.
| Tényező | Eszközön Futó (Edge) AI | Felhőalapú AI |
|---|---|---|
| Késleltetés | Rendkívül alacsony (50 ms alatt), csak a helyi processzor teljesítménye korlátozza. Ideális valós idejű interakciókhoz. | Változó és magasabb, a hálózati sebességtől, a szerver terhelésétől és a távolságtól függ. Nem alkalmas azonnali visszacsatolási ciklusokra. |
| Adatvédelem | Maximális adatvédelem. Alapértelmezés szerint minden adat a felhasználó eszközén marad. | Alacsonyabb adatvédelem. Az adatokat egy harmadik fél szerverére kell küldeni, ami potenciális sebezhetőséget teremt. |
| Kapcsolat | Teljesen működőképes offline. Az AI képességek mindig rendelkezésre állnak, internetkapcsolattól függetlenül. | Működéséhez stabil internetkapcsolat szükséges. Anélkül használhatatlan. |
| Költség | Nincsenek folyamatos szerverköltségek a következtetéshez. Egyszeri költség a szoftverfejlesztésért és integrációért. | Ismétlődő működési költségek az API hívások, adatátvitel és szerver üzemidő alapján. Nagy méretekben drága lehet. |
| Modell Komplexitása | Az eszköz hardvere (RAM, CPU/GPU) korlátozza. A modelleknek kisebbeknek és magasan optimalizáltaknak kell lenniük. | Gyakorlatilag korlátlan. Képes hatalmas, csúcstechnológiás modelleket futtatni több billió paraméterrel. |
| Skálázhatóság és Frissítések | A skálázás decentralizált (eszközönként). A modellfrissítésekhez alkalmazásfrissítések szükségesek a felhasználók számára. | Központilag skálázható. A modellek azonnal frissíthetők a szerveroldalon, felhasználói beavatkozás nélkül. |

Valós Alkalmazások és Jövőbeli Távlatok
Az eszközön futó következtetésre való áttérés nem csupán technikai fejlesztés; teljesen új felhasználói élmények és termékkategóriák létrehozását teszi lehetővé, amelyek korábban kivitelezhetetlenek voltak. A sebesség és az adatvédelem kombinációja hatalmas tervezési teret nyit az innováció számára a fogyasztói és vállalati szektorban egyaránt. A közeljövőben okosabb, reszponzívabb alkalmazásokra számíthatunk, amelyek zökkenőmentesen integrálódnak a mindennapi életünkbe. Gondoljunk egy mobil billentyűzetre, amely valóban hasznos, kontextus-érzékeny írási javaslatokat és fordításokat kínál azonnal, anélkül, hogy a leütéseinket egy szerverre küldené. Vegyük fontolóra az okosotthon-eszközöket, amelyek képesek megérteni és végrehajtani összetett parancsokat természetes nyelven, internetkapcsolat nélkül, biztosítva, hogy még egy kimaradás alatt is működjenek.
Távolabbra tekintve az alkalmazások még átalakítóbbá válnak. Az egészségügyben a viselhető eszközök valós időben elemezhetnék a biometrikus adatokat, hogy személyre szabott egészségügyi tanácsokat vagy korai figyelmeztetéseket adjanak orvosi állapotokra, mindezt a beteg bizalmas adatainak garantálása mellett. Az autóiparban az autós asszisztensek megbízható, másodperc törtrésze alatti válaszokat adhatnának a navigációhoz és a járművezérléshez, a mobilhálózati holt zónáktól függetlenül. A hozzáférhetőség érdekében az okosszemüvegek valós időben leírhatnák a felhasználó környezetét, felolvashatnák a szöveget és felismerhetnék az arcokat, mindezt helyben feldolgozva, hogy biztosítsák mind a sebességet, mind a felhasználó életének pillanatainak magánéletét. Ahogy a mobil hardverek tovább fejlődnek erősebb neurális feldolgozó egységekkel (NPU), a felhőben és a peremhálózaton lehetséges dolgok közötti szakadék tovább szűkül, így az AI jövője intenzíven személyessé, kontextus-érzékennyé és alapvetően emberközpontúbbá válik.
Kihívások és az Út az Edge AI Előtt
Hatalmas potenciálja ellenére az eszközön futó LLM-ek széles körű elterjedéséhez vezető út nem mentes a kihívásoktól. A legjelentősebb akadály továbbra is a mobil és beágyazott eszközök eredendő erőforrás-korlátai. Ellentétben egy adatközpont szinte korlátlan teljesítményével, egy okostelefonnak véges memóriája, feldolgozási kapacitása és akkumulátor-élettartama van. Egy komplex neurális hálózat futtatása energiaigényes feladat, és ha ezt nem hatékonyan teszik, az rossz felhasználói élményhez vezethet az akkumulátor lemerülése és az eszköz túlmelegedése révén. Ez folyamatos innovációt igényel a modelloptimalizálási technikákban, mint például a kvantálás (a modell súlyainak pontosságának csökkentése) és a metszés (a felesleges kapcsolatok eltávolítása a neurális hálózatban), hogy a modelleket anélkül csökkentsék, hogy katasztrofálisan rontanák a teljesítményüket.
Egy másik nagy kihívás a fejlesztési és telepítési életciklusban rejlik. Míg a felhőmodellek központilag és azonnal frissíthetők, az eszközön futó modellek több millió egyedi eszközön vannak elosztva. A frissítések kiküldése megköveteli a felhasználóktól, hogy letöltsék az alkalmazás új verzióit, ami verziófragmentációhoz és a fejlesztések lassabb bevezetéséhez vezet. Továbbá a hardveres ökoszisztéma hihetetlenül változatos. Egy modellt tökéletesen optimalizálni egy csúcskategóriás okostelefonon egy dolog; biztosítani, hogy megbízhatóan működjön több száz különböző középkategóriás és olcsó eszközön, eltérő lapkakészletekkel és memóriakapacitással, sokkal nagyobb logisztikai és mérnöki kihívás. Az előttünk álló út szorosabb együttműködést igényel a modellfejlesztők, a hardvergyártók és az alkalmazáskészítők között, hogy szabványosított, hatékony folyamatokat építsenek ki, amelyek az eszközön futó AI fejlesztését és telepítését olyan zökkenőmentessé teszik, mint a felhőalapú megfelelőjét.
Az eszközön futó AI-ra való áttérés új versenykörnyezetet teremt, ahol a sebesség, az adatvédelem és a felhasználói élmény a legfontosabb. A lokalizált feldolgozás kihasználásával vállalkozása olyan következő generációs alkalmazásokat szállíthat, amelyek gyorsabbak, biztonságosabbak és megbízhatóbbak, mint valaha.
Fejlessze ki Eszközön Futó AI StratégiájátGyakran Ismételt Kérdések
Mit jelent pontosan az eszközön futó LLM következtetés?
Az eszközön futó LLM következtetés azt a folyamatot jelenti, amikor egy nagy nyelvi modellt közvetlenül a felhasználó hardverén, például egy okostelefonon vagy viselhető eszközön futtatnak, ahelyett, hogy az adatokat egy távoli felhőszerverre küldenék feldolgozásra. Ez a megközelítés minden adatot helyben tart, jelentősen csökkentve a késleltetést és növelve az adatvédelmet, mivel az érzékeny információk soha nem hagyják el az eszközt.
Melyek az eszközön futó AI elsődleges előnyei a felhőalapú AI-val szemben?
A legfőbb előnyök a sebesség, az adatvédelem és az offline működés. Az eszközön futó AI kiküszöböli a hálózati késleltetést, szinte azonnali válaszokat biztosítva. Magasabb szintű adatvédelmet kínál, mivel az adatokat nem továbbítják harmadik fél szervereire. Emellett lehetővé teszi az AI funkciók megbízható működését internetkapcsolat nélkül is, ami kulcsfontosságú a mobil és IoT alkalmazások számára.
Hogyan ér el egy Cactus V1-hez hasonló technológia szinte nulla késleltetést?
A Cactus V1 az 50 ms alatti „time-to-first-token” értéket a legnagyobb szűk keresztmetszet, a hálózati körút kiiktatásával éri el. Magasan optimalizált, energiahatékony kernelek és natív futtatókörnyezet használatával a kéréseket közvetlenül az eszköz saját processzorán dolgozza fel. Ez a helyi számítás azt jelenti, hogy az egyetlen késleltetés maga a feldolgozási idő, nem pedig a távoli szerverre és onnan visszaküldött adatokra fordított idő.
Melyek az eszközön futó LLM-ek fő kihívásai vagy korlátai?
Az elsődleges kihívást az erőforrás-korlátok jelentik. A mobileszközök korlátozott processzor teljesítménnyel, memóriával (RAM) és akkumulátor-üzemidővel rendelkeznek a felhőszerverekhez képest. Ez azt jelenti, hogy az eszközön futó modelleknek kisebbeknek és magasan optimalizáltaknak kell lenniük, ami néha korlátozhatja komplexitásukat és képességeiket a hatalmas, szerveralapú modellekhez képest. A hatékony modellkvantálás és a specializált hardver kulcsfontosságú e korlátok leküzdéséhez.
Készen állsz a saját weboldaladra?
Ingyenes konzultáció során átbeszéljük, hogyan segíthetünk vállalkozásodnak növekedni egy modern, gyors és konverzióoptimalizált weboldallal. 14 nap alatt kész, 0 Ft induló költséggel.





