
A hagyományos prompt engineering halott. Az Agentic AI Foundation közelmúltbeli megalakulása és a technológiai óriások állapotfüggő (stateful) API-kra való áttérése egyértelművé tette: a jövő az autonóm ügynököké. A Kontextus Mérnökség (Context Engineering) az a tudomány, amely lehetővé teszi a Nagy Nyelvi Modellek (LLM) számára, hogy emlékezzenek, tervezzenek és cselekedjenek a vállalati adatok alapján. Ez a megközelítés váltja fel a statikus kérdés-válasz rendszereket dinamikus, RAG-alapú architektúrákkal, memóriakezeléssel és fejlett eszközhasználattal, drasztikusan növelve a vállalati ROI-t és az automatizáció megbízhatóságát.
Bevezetés: Az AI Evolúciója – A Prompt Engineeringen Túl
Az elmúlt hetekben az OpenAI és a Google vezetésével megalakult az Agentic AI Foundation, amely egyértelműen jelzi a mesterséges intelligencia iparágának legújabb, tektonikus elmozdulását. A fókusz végérvényesen átkerült a statikus, egyszeri interakciókról a folyamatos, autonóm munkavégzésre.
A "Prompt Engineering", mint a legfontosabb AI készség, gyorsan veszít a jelentőségéből. Bár a modellek pontos utasítása továbbra is fontos, a vállalati szintű problémák megoldásához már nem elegendő egyetlen, jól megfogalmazott mondat. A valódi kihívást az jelenti, hogyan biztosítsuk a modell számára a megfelelő információt a megfelelő időben.
A hagyományos LLM-ek állapotmentesek (stateless). Minden egyes API hívás egy üres lappal indul. Ez a megközelítés tökéletes egy vers megírásához, de teljesen alkalmatlan egy komplex, több lépésből álló egyedi automatizálási folyamat lebonyolításához, ahol a korábbi lépések eredményei határozzák meg a következőket.
Itt lép be a képbe a Kontextus Mérnökség (Context Engineering). Ez az új paradigma nem a modell belső súlyainak megváltoztatásáról szól, hanem a modell köré épített intelligens információs architektúráról. Arról, hogyan építünk fel egy olyan rendszert, amely képes dinamikusan kezelni a memóriát, lekérdezni a releváns vállalati adatokat, és autonóm módon használni külső szoftveres eszközöket.
A Generatív AI és az Agentikus AI közötti különbség pontosan ebben a kontextuskezelési képességben rejlik. A modern CTO-k számára a kérdés már nem az, hogy melyik modellt használják, hanem az, hogy milyen kontextuális infrastruktúrát építenek köré.
Mi az a Kontextus Mérnökség? Az Új Paradigma Meghatározása
Definíció: Kontextus Mérnökség (Context Engineering)
A Kontextus Mérnökség egy szoftverarchitekturális és adatkezelési diszciplína, amely az LLM-ek (Nagy Nyelvi Modellek) körüli információs környezet dinamikus összeállítására, optimalizálására és fenntartására fókuszál. Célja, hogy az állapotmentes modelleket állapotfüggő (stateful), kontextus-tudatos ügynökökké alakítsa, amelyek képesek hosszú távú memóriakezelésre, valós idejű adatlekérdezésre és komplex, több lépéses feladatok autonóm végrehajtására.
A kontextus mérnökség alapvetően különbözik a prompt engineeringtől. Míg a prompt engineering a bemeneti szöveg nyelvi finomhangolására összpontosít (pl. "viselkedj úgy, mint egy szakértő"), addig a kontextus mérnökség a bemeneti adatok rendszerszintű biztosítására fókuszál.
Képzeljünk el egy új alkalmazottat. A prompt engineering olyan, mintha nagyon pontosan elmagyaráznánk neki a feladatát, de nem adnánk neki hozzáférést a céges dokumentumokhoz, az e-mailekhez vagy a korábbi projektek aktáihoz. Bármilyen okos is az alkalmazott, adatok nélkül nem tud dolgozni.
A kontextus mérnökség ezzel szemben biztosítja a teljes munkakörnyezetet. Kiépíti azokat az adatcsatornákat (data pipelines), amelyek valós időben szállítják a releváns információkat a modell kontextus ablakába (context window). Ez magában foglalja a strukturálatlan adatok feldolgozását, a vektoros beágyazásokat (embeddings), és a komplex visszakeresési algoritmusokat.
A legfontosabb különbség az állapot (state) kezelésében rejlik. Egy kontextus-mérnök által tervezett rendszer képes fenntartani a beszélgetés fonalát órákon, napokon vagy akár heteken keresztül is, folyamatosan frissítve a saját belső tudásbázisát az új interakciók alapján.

A Kontextus Mérnökség Pillérei: Állapotfüggő LLM Ügynökök Építése
Egy robusztus, vállalati szintű AI ügynök felépítése nem egyetlen technológián múlik. A kontextus mérnökség három fő pillérre támaszkodik, amelyek szorosan integrálva alkotják meg az intelligens, autonóm rendszert. Ezek a pillérek biztosítják, hogy az AI ne csak "beszéljen", hanem értsen, emlékezzen és cselekedjen is.
Lekérdezés-alapú Generáció (RAG): A Releváns Kontextus Alapja
A Retrieval-Augmented Generation, vagyis a RAG AI chatbotok technológiája a kontextus mérnökség legfontosabb alapköve. A RAG oldja meg az LLM-ek legnagyobb problémáját: a hallucinációt és az elavult vagy hiányzó vállalati tudást.
A RAG architektúra lényege, hogy mielőtt a nyelvi modell válaszolna egy kérdésre, a rendszer először keresést végez egy külső tudásbázisban. Ez a tudásbázis általában egy vektoradatbázis (pl. Pinecone, Qdrant, Milvus), amely a vállalati dokumentumokat matematikai vektorok (embeddings) formájában tárolja.
A folyamat rendkívül technikai. Amikor a felhasználó feltesz egy kérdést, egy beágyazási modell (pl. OpenAI text-embedding-3-large) a kérdést is vektorrá alakítja. A vektoradatbázis ezután kiszámítja a koszinusz-hasonlóságot (cosine similarity) a kérdés vektora és a tárolt dokumentum-vektorok között, hogy megtalálja a leginkább releváns szövegrészleteket.
A fejlett kontextus mérnökség azonban nem áll meg az egyszerű szemantikai keresésnél. A modern rendszerek hibrid keresést (Hybrid Search) alkalmaznak, amely ötvözi a vektoros keresést a hagyományos kulcsszavas kereséssel (BM25 algoritmus). Ez biztosítja, hogy mind a koncepcionális egyezések, mind a pontos kulcsszavak (pl. cikkszámok, nevek) megtalálhatók legyenek.
Ezután következik a Re-ranking fázis. Egy speciális modell (Cross-Encoder) újraértékeli és sorrendbe állítja a megtalált dokumentumokat, hogy a legrelevánsabbak kerüljenek a lista elejére. Csak ezután illesztjük be ezeket a szövegeket az LLM kontextus ablakába, mint "tényeket", amelyek alapján a modell generálja a végső választ.

Memóriakezelés: Állapotfüggő Interakciók Engedélyezése
Míg a RAG a külső, statikus tudás elérését biztosítja, a memóriakezelés az interakciók dinamikus történetének megőrzéséért felel. Enélkül az AI ügynök minden lépésnél elfelejtené, hogy mit csinált az előző másodpercben, ami az architekturális amnézia jelenségéhez vezet.
A kontextus mérnökök háromféle memóriaszintet különböztetnek meg és implementálnak. Az első a Rövid távú memória (Short-term memory), amely magában a kontextus ablakban (context window) él. Ez tartalmazza az aktuális beszélgetés utolsó néhány üzenetét. Mivel a kontextus ablak mérete korlátozott (bár egyre nő, pl. Claude 3.5 Sonnet esetében 200k token), ezt a memóriát folyamatosan menedzselni kell.
A memóriamenedzsment technikái közé tartozik a régebbi üzenetek automatikus összegzése (summarization), vagy a kevésbé releváns üzenetek eldobása (sliding window). A cél az, hogy a modell mindig lássa a beszélgetés fonalát, de ne pazaroljuk a drága tokeneket felesleges információkra.
A második szint a Hosszú távú memória (Long-term memory). Ez általában egy relációs adatbázisban (pl. PostgreSQL) vagy NoSQL adatbázisban tárolt állapotgráf (state graph). Frameworkök, mint a LangGraph, lehetővé teszik a fejlesztők számára, hogy a teljes ügynöki folyamatot csomópontokként (nodes) és élekként (edges) definiálják, ahol az állapot (state) minden lépés után perzisztensen mentésre kerül.
A harmadik szint a Szemantikus memória (Semantic memory), amely a felhasználóról vagy a környezetről tanult tényeket tárolja vektoros formában. Ha a felhasználó megemlíti, hogy "a projekt határideje péntek", az ügynök ezt a tényt kinyeri, és elmenti a memóriájába, hogy a jövőbeli interakciók során automatikusan felhasználhassa, anélkül, hogy a felhasználónak újra meg kellene ismételnie.
Ügynöki Tervezés és Eszközhasználat: Az LLM-ek és a Cselekvés Összekapcsolása
A kontextus mérnökség harmadik pillére az, ami a passzív chatbotokat aktív adatfeldolgozó AI-ügynökökké alakítja. Ez a képesség teszi lehetővé a modellek számára, hogy kilépjenek a szöveggenerálás dobozából, és valós műveleteket hajtsanak végre a digitális világban.
Az eszközhasználat (Tool Use vagy Function Calling) technikai megvalósítása során a fejlesztők egy JSON sémát biztosítanak az LLM számára, amely leírja az elérhető funkciókat (pl. `get_weather`, `query_database`, `send_email`), azok paramétereit és típusait. A modell, ha a kontextus úgy kívánja, nem szöveget generál, hanem egy strukturált JSON objektumot, amely egy konkrét funkció meghívását kéri.
A rendszer (az orchestrator) elfogja ezt a kérést, végrehajtja a tényleges kódot (pl. meghív egy külső API-t), majd az eredményt visszatáplálja az LLM kontextusába. Ez a folyamat iteratív. Az ügynök képes értékelni az eredményt, és ha hibát észlel, újra próbálkozhat más paraméterekkel.
A komplex feladatok megoldásához a kontextus mérnökök olyan promptolási és architekturális keretrendszereket használnak, mint a ReAct (Reasoning and Acting). A ReAct keretrendszer arra kényszeríti a modellt, hogy mielőtt cselekedne (Act), írja le a gondolatmenetét (Thought). Ez a belső monológ drasztikusan javítja a modell tervezési képességeit és a több lépéses problémamegoldás megbízhatóságát.
Fejlett vállalati környezetben gyakran több, specializált ügynök dolgozik együtt (Multi-Agent Systems). Egy "Tervező" ügynök felbontja a komplex feladatot részfeladatokra, amelyeket "Végrehajtó" ügynököknek delegál, miközben egy "Értékelő" ügynök ellenőrzi a minőséget. A kontextus mérnökség feladata ezen ügynökök közötti információs áramlás és kontextus-megosztás hibátlan biztosítása.
Miért Fontos a Kontextus Mérnökség a Vállalatok Számára?
A kontextus mérnökség nem csupán egy technológiai érdekesség; ez a kulcsa a mesterséges intelligencia vállalati szintű, megtérülő (ROI-pozitív) alkalmazásának. A hagyományos, dobozos AI megoldások gyakran elbuknak a vállalati valóság komplexitásán, mert hiányzik belőlük a specifikus üzleti kontextus.
Az első és legfontosabb üzleti előny a pontosság és a megbízhatóság drasztikus növekedése. A hallucinációk – amikor az AI magabiztosan állít valótlanságokat – a legnagyobb akadályát jelentik a vállalati adaptációnak. A kontextus mérnökség (különösen a RAG) a válaszokat szigorúan a vállalat saját, ellenőrzött adataihoz horgonyozza, minimalizálva a kockázatot.
Másodszor, a kontextus-tudatos ügynökök lehetővé teszik a hiper-perszonalizációt méretarányosan. Egy ügyfélszolgálati AI, amely azonnal hozzáfér a hívó fél teljes vásárlási történetéhez, korábbi panaszaihoz és aktuális szerződéses feltételeihez, olyan szintű kiszolgálást nyújt, amely korábban csak a legkiválóbb emberi operátoroktól volt elvárható.
Harmadszor, a fejlett eszközhasználat és memóriakezelés megnyitja az utat a komplex, end-to-end folyamatok automatizálása előtt. Nem csak arról van szó, hogy az AI megválaszol egy e-mailt. Arról van szó, hogy az AI elolvassa az e-mailt, kinyeri a számlaadatokat, ellenőrzi az ERP rendszerben a teljesítést, jóváhagyja a kifizetést, és végül értesíti a partnert. Ez a szintű egyedi automatizálás radikálisan csökkenti a működési költségeket.
Kulcsfontosságú Kihívások a Kontextus Mérnökség Nagy Léptékű Bevezetésében
Bár a kontextus mérnökség hatalmas potenciállal bír, a vállalati szintű implementáció komoly technikai és szervezeti kihívásokkal jár. A prototípus fázisból a termelésbe (production) való átmenet gyakran rávilágít a rendszerek törékenységére.
Az egyik legnagyobb technikai kihívás a kontextus ablak korlátainak kezelése. Bár a modellek egyre több tokent képesek befogadni, a "tű a szénakazalban" (needle in a haystack) probléma továbbra is fennáll. Ha túl sok irreleváns információval árasztjuk el a modellt, a figyelmi mechanizmus (attention mechanism) felhígul, és a modell hajlamos figyelmen kívül hagyni a kritikus részleteket. A kontextus mérnököknek precíz szűrési és rangsorolási algoritmusokat kell alkalmazniuk.
A késleltetés (latency) és a számítási költségek szintén kritikus tényezők. A komplex RAG pipeline-ok, amelyek több adatbázis-lekérdezést, beágyazás-generálást és újra-rangsorolást foglalnak magukban, jelentősen megnövelhetik a válaszidőt. A valós idejű alkalmazásoknál (pl. hangalapú AI asszisztensek) a milliszekundumok is számítanak. A pipeline optimalizálása és a gyorsítótárazás (caching) elengedhetetlen.
Végül, az adatminőség és az adatkormányzás (data governance) alapvető fontosságú. A RAG rendszer csak annyira jó, mint a mögötte lévő adatok. Ha a vállalati tudásbázis tele van elavult, ellentmondásos vagy strukturálatlan dokumentumokkal, a kontextus mérnökség csak felerősíti a káoszt. Az adatok tisztítása és folyamatos karbantartása az AI bevezetés előfeltétele.
Vállalati Szintű LLM Ügynökök Tervezése Kontextus Mérnökséggel
Egy vállalati szintű, kontextus-vezérelt AI rendszer tervezése túlmutat egy egyszerű Python script megírásán. Robusztus, skálázható és biztonságos architektúrát igényel, amely illeszkedik a meglévő IT infrastruktúrába.
Architekturális Megfontolások: Adatfolyam és Integráció
A rendszer magja az orchestrator réteg (pl. LangChain, LlamaIndex, vagy egyedi mikroszolgáltatások). Ez a réteg felelős a felhasználói kérések fogadásáért, a kontextus összeállításáért, az LLM meghívásáért és a válaszok feldolgozásáért. Az orchestratornak aszinkron módon kell működnie, hogy ne blokkolja a rendszert a hosszú ideig tartó LLM hívások alatt.
Az adatfolyam (data pipeline) kritikus komponens. A vállalati adatok (SharePoint, Confluence, Jira, ERP rendszerek) folyamatosan változnak. Olyan ETL (Extract, Transform, Load) folyamatokat kell kiépíteni, amelyek valós időben vagy gyakori ütemezéssel kinyerik az új adatokat, feldarabolják őket (chunking), beágyazásokat generálnak, és frissítik a vektoradatbázist. A chunking stratégia (pl. szemantikai alapú darabolás vs. fix karakterhossz) alapvetően meghatározza a visszakeresés minőségét.
Az integráció során API gateway-eket és eseményvezérelt architektúrákat (pl. Kafka, RabbitMQ) érdemes használni, hogy az AI ügynökök zökkenőmentesen kommunikálhassanak a belső rendszerekkel, és reagálhassanak a rendszereseményekre (pl. új ügyfél regisztrációja).
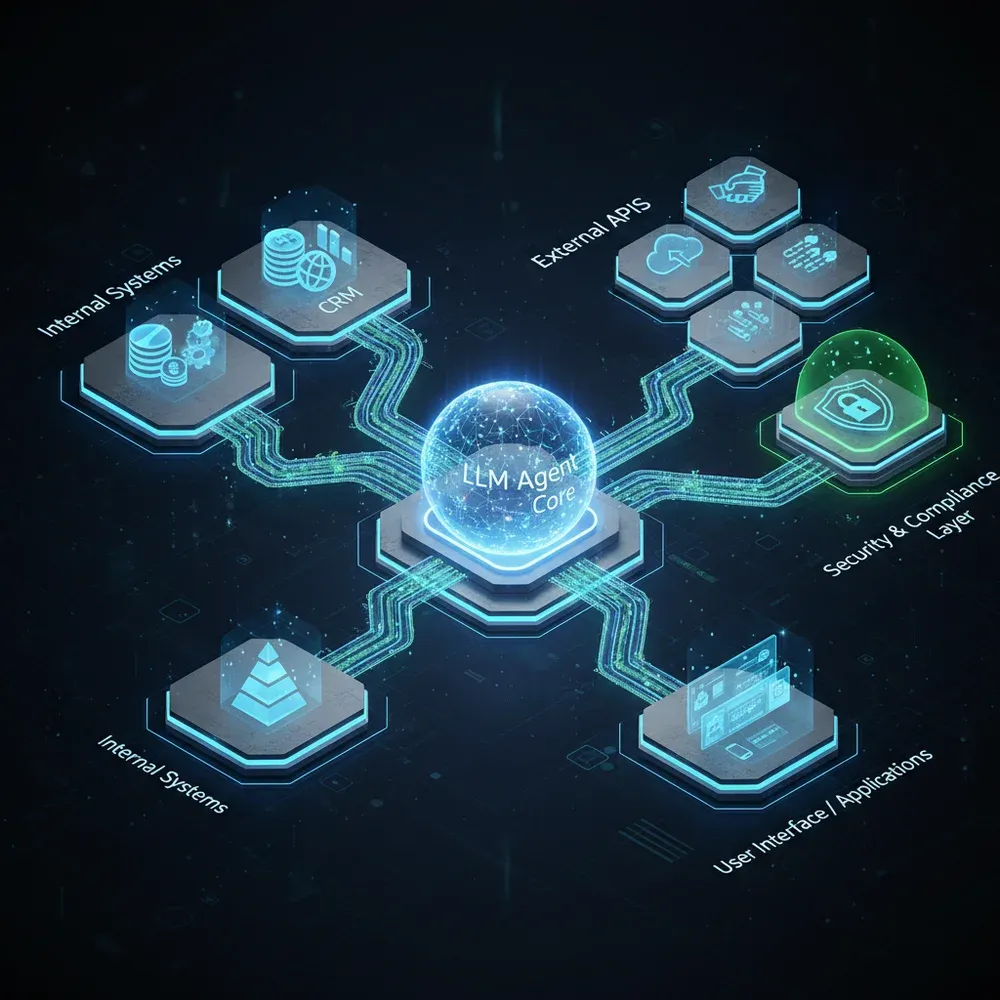
Biztonság és Megfelelőség a Kontextusban Gazdag Rendszerekben
A kontextus mérnökség egyik legnagyobb kihívása a biztonság. Mivel a rendszer dinamikusan húz be adatokat a vállalati tudásbázisból, szigorú hozzáférés-szabályozást (RBAC - Role-Based Access Control) kell implementálni. Az AI ügynök nem láthat olyan dokumentumokat, amelyekhez a kérdező felhasználónak nincs jogosultsága.
Ezt a vektoradatbázis szintjén kell megoldani, metaadat-szűréssel (metadata filtering). Minden dokumentum-darabkához (chunk) hozzá kell rendelni a megfelelő jogosultsági címkéket, és a vektoros keresést ezen címkék alapján kell szűrni, még mielőtt az eredmények az LLM-hez kerülnének.
A megfelelőség (GDPR, HIPAA, SOC2) érdekében a PII (Personally Identifiable Information) és PHI (Protected Health Information) adatokat maszkolni vagy anonimizálni kell, mielőtt azok bekerülnének a vektoradatbázisba vagy az LLM kontextusába. Különösen fontos ez, ha külső, felhőalapú LLM szolgáltatókat (pl. OpenAI, Anthropic) használunk. Az audit naplózás (audit logging) elengedhetetlen: pontosan nyomon kell követni, hogy az AI milyen adatokat használt fel egy adott válasz generálásához.
Teljesítményoptimalizálás Állapotfüggő Ügynökök Számára
A teljesítményoptimalizálás több szinten történik. A leggyorsabb és legköltséghatékonyabb módszer a szemantikus gyorsítótárazás (Semantic Caching). Ha egy felhasználó egy olyan kérdést tesz fel, amely szemantikailag nagyon hasonló egy korábban már megválaszolt kérdéshez, a rendszer nem futtatja le a teljes RAG pipeline-t és az LLM hívást, hanem a gyorsítótárból szolgálja ki a választ.
A szemantikus útválasztás (Semantic Routing) egy másik hatékony technika. Egy gyors, olcsóbb modell (vagy egy egyszerű osztályozó algoritmus) elemzi a bejövő kérést, és eldönti, hogy a feladat egyszerű (pl. jelszó visszaállítás), vagy komplex (pl. pénzügyi elemzés). Az egyszerű feladatokat olcsóbb modellekhez (pl. GPT-4o-mini) vagy hagyományos kódhoz irányítja, míg a komplexeket a drágább, intelligensebb modellekhez (pl. Claude 3.5 Sonnet).
A vektoradatbázis optimalizálása is kritikus. Az indexelési algoritmusok (pl. HNSW - Hierarchical Navigable Small World) finomhangolása jelentősen csökkentheti a keresési időt nagy adathalmazok esetén.
Kontextus Mérnökség vs. Finomhangolás: Stratégiai Összehasonlítás
Gyakori kérdés a vállalati AI stratégiában: "Finomhangoljuk (fine-tune) a modellt a saját adatainkon, vagy használjunk RAG-ot és kontextus mérnökséget?" A válasz szinte mindig az utóbbi, vagy a kettő kombinációja.
A finomhangolás során a modell belső súlyait (weights) módosítjuk új tanító adatok segítségével. Ez kiválóan alkalmas arra, hogy megtanítsuk a modellt egy specifikus stílusra, hangnemre (tone of voice), vagy egy új, speciális formátumra (pl. egyedi JSON struktúra generálása). Azonban a finomhangolás rendkívül rossz módszer új ténybeli tudás betáplálására.
A modellek hajlamosak elfelejteni a finomhangolás során tanult tényeket (catastrophic forgetting), és a tudás frissítése minden alkalommal új, költséges tanítási folyamatot igényel. Ezzel szemben a kontextus mérnökség (RAG) elválasztja a tudást a modelltől. Az adatok frissítése csupán a vektoradatbázis frissítését jelenti, ami valós időben, minimális költséggel elvégezhető.
Összehasonlító Táblázat: Kontextus Mérnökség vs. Finomhangolás
| Jellemző | Kontextus Mérnökség (RAG) | Finomhangolás (Fine-Tuning) |
|---|---|---|
| Fő cél | Ténybeli tudás és kontextus biztosítása | Stílus, formátum és viselkedés módosítása |
| Adatfrissítés | Valós idejű, egyszerű (DB frissítés) | Lassú, költséges (újratanítás szükséges) |
| Hallucináció kockázata | Alacsony (forrásokra hivatkozik) | Magas (a modell saját magára hagyatkozik) |
| Költség | Alacsony beállítási, magasabb futtatási (tokenek) | Magas beállítási, alacsonyabb futtatási |
| Jogosultságkezelés | Könnyen implementálható (DB szinten) | Szinte lehetetlen (a modell mindent tud) |
Az AI Jövője: Kontextus által Meghajtott Autonóm Ügynökök
A kontextus mérnökség fejlődése egyenes utat nyit a teljesen autonóm, több-ügynökös rendszerek (Multi-Agent Systems) felé. A jövő vállalataiban nem emberek fognak promptokat írni az AI-nak. Ehelyett magas szintű üzleti célokat fognak megfogalmazni, amelyeket az AI ügynökök hálózata önállóan bont le feladatokra, tervezi meg a végrehajtást, gyűjti be a szükséges kontextust, és hajtja végre a műveleteket.
Ezek az ügynökök folyamatosan tanulni fognak a környezetükből. A memóriakezelési rendszerek fejlődésével az ügynökök megértik a vállalati hierarchiát, a rejtett folyamatokat és a felhasználói preferenciákat. Ez a szintű intelligencia elképzelhetetlen a kontextus mérnökség szigorú, mérnöki alapjai nélkül.

Esettanulmányok: A Kontextus Mérnökség a Gyakorlatban (Példák)
A pénzügyi szektorban a kontextus mérnökség forradalmasítja a kockázatelemzést. Egy befektetési banknál implementált RAG-alapú ügynök valós időben képes elemezni több ezer oldalnyi pénzügyi jelentést, tőzsdei híreket és belső elemzéseket. Az ügynök nem csak összefoglalja az adatokat, hanem komplex lekérdezéseket hajt végre a vektoradatbázisban, hogy azonosítsa a rejtett piaci trendeket, drasztikusan felgyorsítva a döntéshozatalt.
Az egészségügyben az állapotfüggő ügynökök a betegutak menedzselésében nyújtanak áttörést. Egy kontextus-tudatos AI asszisztens biztonságosan hozzáfér a páciens anonimizált kórtörténetéhez (hosszú távú memória), integrálódik a laboratóriumi rendszerekkel (eszközhasználat), és képes előzetes diagnosztikai javaslatokat tenni az orvosok számára, miközben minden lépést szigorúan naplóz a HIPAA megfelelőség érdekében.
A B2B ügyfélszolgálat területén a kontextus mérnökség megszünteti a frusztráló, menüvezérelt chatbotokat. Egy intelligens ügynök, amely ismeri a partnercég teljes szerződéses hátterét, korábbi hibajegyeit és aktuális rendeléseit, képes azonnal, emberi szintű empátiával és pontossággal megoldani a komplex logisztikai problémákat, automatikusan módosítva a szállítási adatokat az ERP rendszerben.
Válassza ki a Megfelelő Partnert Kontextus Mérnökségi Útjához
A kontextus mérnökség bevezetése nem egy dobozos szoftver telepítése; ez egy komplex rendszerintegrációs projekt. Olyan partnerre van szüksége, aki nem csak a nyelvi modelleket ismeri, hanem mélyreható tapasztalattal rendelkezik az adatmérnökség, a felhőarchitektúrák és a vállalati biztonság terén.
Az AiSolve-nál mi pontosan erre specializálódtunk. Legyen szó egy biztonságos, belső tudásbázison alapuló AI Chatbot (RAG) bevezetéséről, vagy komplex adatfeldolgozó AI-ügynökök fejlesztéséről, mérnökeink a legmodernebb kontextus mérnökségi elveket alkalmazzák. Segítünk átalakítani a statikus adatait dinamikus, cselekvőképes intelligenciává.
Következtetés: Lépjen be az Ügynöki Jövőbe a Kontextus Mérnökséggel
A prompt engineering korszaka lezárult. A jövő a kontextus mérnökségé. Azok a vállalatok, amelyek felismerik, hogy az AI valódi ereje nem a modellek méretében, hanem a köréjük épített intelligens, állapotfüggő és adatközpontú architektúrában rejlik, behozhatatlan versenyelőnyre tesznek szert.
Ne érje be egyszerű chatbotokkal, amelyek minden beszélgetést tiszta lappal kezdenek. Építsen olyan autonóm rendszereket, amelyek emlékeznek, tanulnak és cselekszenek. Lépjen kapcsolatba velünk még ma, és kezdjük el megtervezni vállalata kontextus-vezérelt AI jövőjét.
Gyakori Kérdések (FAQ)
Mennyire biztonságos a Kontextus Mérnökség érzékeny vállalati adatokkal?
Rendkívül biztonságos, ha megfelelően implementálják. A kontextus mérnökség lehetővé teszi a szigorú, dokumentum-szintű hozzáférés-szabályozást (RBAC) a vektoradatbázisokban. Az adatok maszkolhatók a beágyazás előtt, és a rendszer futtatható zárt, privát felhőkörnyezetben (VPC) vagy akár helyi (on-premise) szervereken is, garantálva, hogy az érzékeny adatok soha nem hagyják el a vállalat hálózatát.
Milyen iparágak profitálhatnak leginkább a Kontextus Mérnökségből?
Bár minden adatalapú iparág profitálhat belőle, a legnagyobb ROI-t azok a szektorok realizálják, ahol komplex tudásbázisokat és szigorú szabályozásokat kell kezelni. Ilyen a pénzügy (kockázatelemzés, compliance), a jog (szerződéselemzés, precedens-kutatás), az egészségügy (betegadat-kezelés, diagnosztikai támogatás) és a komplex B2B gyártás vagy logisztika.
Miben különbözik a Kontextus Mérnökség a hagyományos adatbázis-integrációtól?
A hagyományos integráció merev, SQL-alapú lekérdezésekre épül, amelyek pontos egyezést igényelnek. A kontextus mérnökség vektoros beágyazásokat és szemantikus keresést használ, így az AI képes megérteni az adatok jelentését és összefüggéseit, még akkor is, ha a felhasználó nem a pontos kulcsszavakat használja. Emellett dinamikusan kezeli a memóriát és az állapotot az interakciók során.
Mekkora befektetésre van szükség egy vállalati szintű Kontextus Mérnökségi rendszer bevezetéséhez?
A befektetés mértéke a projekt komplexitásától, az integrálandó adatforrások számától és a biztonsági követelményektől függ. Egy alapvető, belső dokumentumokra épülő RAG rendszer bevezetése már néhány millió forinttól elérhető, míg egy komplex, több-ügynökös, ERP-vel integrált autonóm rendszer komolyabb, stratégiai beruházást igényel. A ROI azonban a legtöbb esetben 6-12 hónapon belül jelentkezik a drasztikus hatékonyságnövekedés révén.
Lehetséges-e a Kontextus Mérnökséget meglévő LLM megoldásokkal integrálni?
Igen, abszolút. A kontextus mérnökség modell-agnosztikus. Az architektúra (vektoradatbázisok, orchestratorok, memóriakezelés) független attól, hogy a végén OpenAI GPT-4o, Anthropic Claude 3.5, vagy egy nyílt forráskódú, helyben futtatott Llama 3 modellt használunk. Ez rugalmasságot biztosít a vállalatok számára a modellek jövőbeli cseréjéhez.
Milyen mérőszámokat használjunk a Kontextus Mérnökség sikerének mérésére?
A technikai mérőszámok közé tartozik a visszakeresési pontosság (Retrieval Accuracy - pl. MRR, NDCG), a válaszidő (Latency) és a hallucinációs ráta. Az üzleti mérőszámok sokkal fontosabbak: a feladatok automatizálási aránya (Task Completion Rate), az emberi beavatkozás szükségességének csökkenése (Deflection Rate), és a folyamatok átfutási idejének (Turnaround Time) rövidülése.


