
Modern businesses are driven by data, but accessing, processing, and analyzing this data has traditionally required costly and complex infrastructure. Imagine a world where all you need to analyze petabyte-scale datasets is a web browser. This vision has now become a reality thanks to DuckDB's latest development, which enables direct interaction with Apache Iceberg data catalogs from the browser. This technological breakthrough is not just a technical curiosity; it could fundamentally change how we think about data access and how future data processing AI agents operate. A recent report from InfoQ states that DuckDB-Wasm, the WebAssembly port of DuckDB, now allows for serverless data interaction, providing developers and data analysts with unprecedented flexibility.
This revolutionary approach eliminates the intermediary layers—backend APIs, data proxies, and complex authentication flows—that were previously essential for communication between a browser and large-scale data storage like S3. Users can now run SQL queries on massive Iceberg tables directly from their browser without setting up a single server. This paradigm shift dramatically lowers the barrier to entry for big data analytics and opens up new possibilities for interactive, real-time data visualization tools and more complex, client-side analytical applications. In this article, we will conduct a deep dive into how this technology works, its business advantages, its inherent challenges, and how it is reshaping the development of data-driven solutions, especially data processing AI agents.
| Terület / Area | Kulcsfontosságú Megállapítás / Key Insight |
|---|---|
| Serverless Access | DuckDB-Wasm enables direct, browser-based SQL queries on Apache Iceberg tables, eliminating the need for server-side infrastructure. |
| Cost-Effectiveness | Eliminating intermediary layers (APIs, proxies) drastically reduces development, operational, and computational costs. |
| Data Democratization | Simplifies data access, allowing more users (analysts, developers) to interact directly with big data systems. |
| AI Integration | This technology opens new avenues for data processing AI agents to deliver data more effectively on user interfaces. |
| User Experience | It enables the development of highly interactive, real-time data visualization and analytical applications that run directly in the browser. |
The New Dawn of Serverless Data Analytics
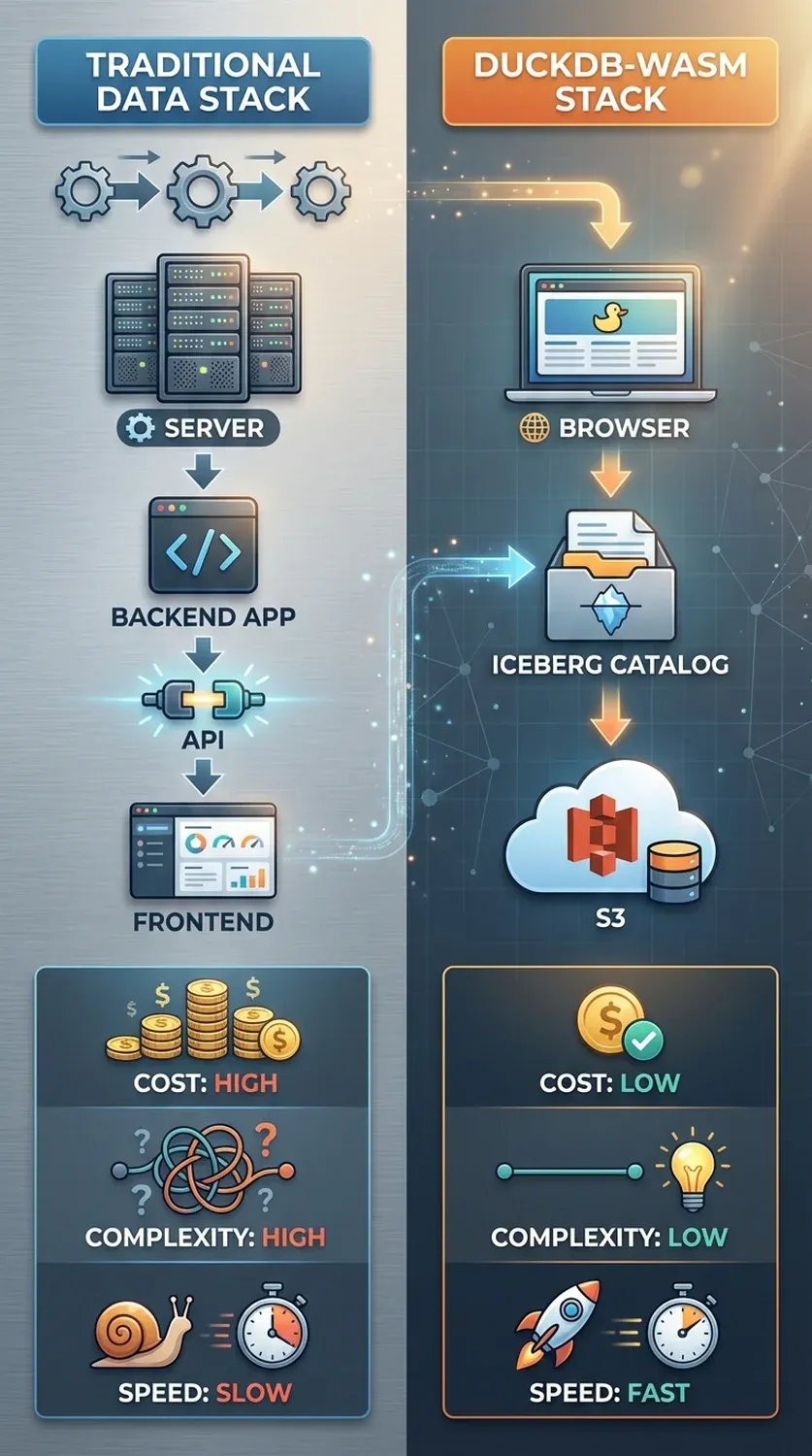
In the age of data-driven decision-making, the biggest challenge for businesses is often not collecting data, but accessing it efficiently and quickly. Traditional data architectures consist of multiple layers: data resides in a data lake or warehouse, a backend application is responsible for querying it, an API serves the results, and finally, a frontend application displays them to the user. Each layer adds complexity, latency, and cost to the process. The browser-based integration of DuckDB and Apache Iceberg completely upends this model. By moving the query logic to the client-side—the user's browser—it creates a radically simplified, serverless architecture.
This approach takes the principle of "moving compute to the data" to a whole new level. Instead of moving vast amounts of data across the network to a central server for processing, the browser itself becomes a mini-data processing hub. It only downloads the necessary data directly from S3-compatible storage and performs the processing locally. This not only reduces network traffic and server load but also provides unparalleled interactivity. Users can explore data in real-time without delay, as if it were on their own machine. This new era fundamentally changes the development of data analysis tools and applications driven by intelligent systems, such as advanced data processing AI agents.
The Technological Trinity: DuckDB, WebAssembly, and Apache Iceberg
To understand the significance of this innovation, it's worth examining the three key technologies that make this magic possible. Each is an important piece of the puzzle, and together they form an incredibly powerful system.
DuckDB: The Swiss Army Knife of Analytics
DuckDB is an in-process analytical database management system (OLAP). It is often referred to as the "SQLite for analytics." It is specifically designed to run fast and efficient analytical queries without needing to run a separate server process. It's compact, fast, and extremely efficient, making it ideal for resource-constrained environments like a browser.
WebAssembly (Wasm): Native Speed on the Web
WebAssembly is a binary instruction format that allows code written in high-level languages (like C++, Rust) to run in web browsers at near-native speed. DuckDB-Wasm is the version of the DuckDB engine compiled to Wasm. This allows the full, high-performance analytical database engine to run directly alongside the browser's JavaScript engine, leveraging the capabilities of modern hardware.
Apache Iceberg: The Format for Reliable Data Tables
Apache Iceberg is an open table format designed for huge analytical datasets. It essentially forms an abstraction layer over files (e.g., Parquet, ORC) that provides database-like features such as ACID transactions, time travel, and schema evolution directly on data lakes. The Iceberg REST catalog provides the metadata about which files belong to a specific table, allowing DuckDB-Wasm to know exactly which data to download and process.
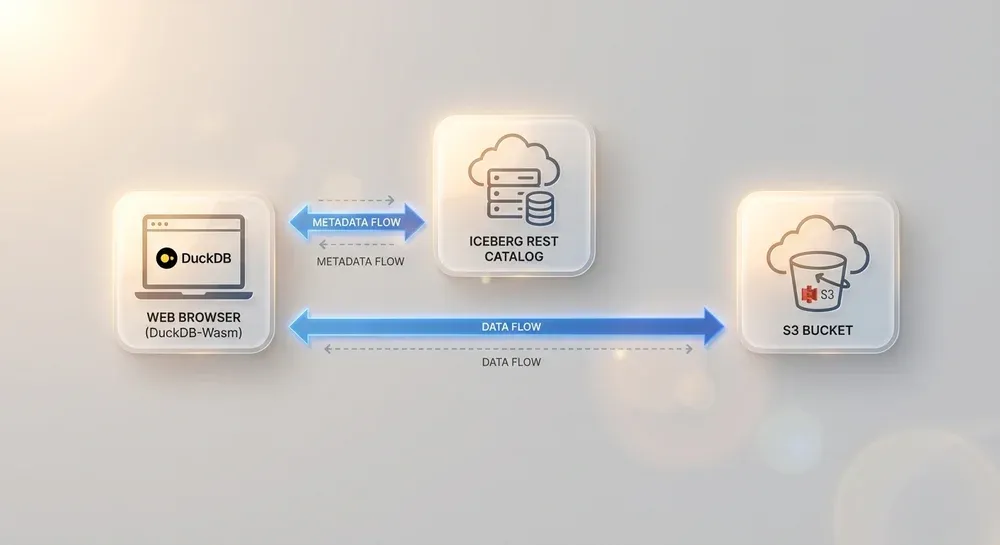
How It Works: The Browser as a Database Client
The process is elegantly simple yet incredibly powerful. When a user interacts with such a web application and initiates a query, the following steps happen behind the scenes, all within the browser:
- Query Initiation: The user initiates an SQL query through a web interface (e.g., by clicking on a chart or setting a filter).
- Metadata Request: The DuckDB-Wasm client running in the browser sends an HTTP request to the Iceberg REST catalog. This request is for the table's metadata, not the actual data.
- File List Reception: The catalog responds with a list of the Parquet (or other format) files and their exact location in S3 that are relevant to the query.
- Direct Data Download: DuckDB-Wasm uses the browser's built-in `fetch` API with HTTP Range requests to download the required data directly from the S3-compatible storage. Range requests are crucial because they allow downloading only the relevant parts of files (e.g., the necessary columns or row groups), minimizing network traffic.
- Local Processing: Once the data is in the browser's memory, the DuckDB-Wasm engine executes complex SQL operations (filtering, aggregation, joins) on it, using the user's machine's processor.
- Result Display: The results are immediately passed to the JavaScript layer, which updates the user interface, such as an interactive chart or table.
This model effectively transforms the browser from a thin client into a thick, data-processing-capable client. This capability allows the results of sophisticated backend data processing AI agents to be explored dynamically and interactively by users, without requiring server-side computation for every interaction.
Business Advantages: Cost Reduction, Scalability, and Democratized Data Access
The appeal of this technology extends far beyond its technical elegance; it offers tangible business benefits for companies. One of the most significant advantages is a dramatic reduction in costs. Operating server-side query engines, API gateways, and the associated infrastructure incurs significant expenses, both in hardware and human resources. By shifting this load to the user's side, computational costs are virtually eliminated, as the processing is handled by the users' devices. This makes it particularly attractive for ad-hoc analytical tasks and rapid prototyping.
Strategic Insight: Start by building a prototype of an internal analytics dashboard with this technology. The speed of development and low costs allow for rapid iteration without investing in expensive backend infrastructure.
Scalability is another key benefit. In traditional systems, a growing number of users means an increased load on servers, necessitating vertical or horizontal scaling. With this serverless model, the system scales naturally: each new user brings their own resources. The system can serve as many users as connect without overwhelming the central infrastructure. Finally, this technology democratizes access to data. By removing technical barriers, it allows a wider range of people to interact directly with data without having to rely on the IT department or data engineers. This encourages exploration, experimentation, and ultimately fosters a more data-driven corporate culture.
The User Interfaces of the Future: Where the Work of Data Processing AI Agents Becomes Visible
This browser-based processing capability aligns perfectly with the evolution of AI-driven systems, especially data processing AI agents. Imagine a system where AI models running in the background continuously analyze incoming data, look for anomalies and patterns, and then write the results and raw data to an Iceberg table. Users can then explore these results in great detail and interactively through a web interface using DuckDB-Wasm. For example, a marketing analyst could filter, group, and visualize billions of rows of campaign data in real-time to understand the cause of an anomaly, without initiating a single server-side query.
This is where professional website creation becomes crucial. To harness such powerful client-side processing capabilities, a simple website is not enough. It requires sophisticated, responsive, and intuitive user interfaces that can handle dynamic data visualizations, complex filters, and interactive controls. The user experience (UX) design must consider that the user now wields the full power of a data analysis tool in their browser. Effective website creation ensures that this power is empowering rather than overwhelming, allowing users to gain deeper insights from their data.
| Feature | Traditional Web App | DuckDB-Wasm Powered App |
|---|---|---|
| Data Processing Location | Central Server | User's Browser |
| Interactivity | High Latency (Network Round-trips) | Instant, Real-time |
| Infrastructure Cost | High (Compute, Operations) | Minimal (Storage Only) |
| Scalability | Complex, Costly | Automatic, Proportional to Users |
| Backend Development | Required (APIs, Data Logic) | Often Unnecessary |
Challenges and Limitations: What to Watch Out For in Browser-Based Data Processing
While browser-based data analytics is extremely promising, it is important to be aware of its limitations. One of the most obvious challenges is the browser's memory and processor constraints. Although modern browsers and devices are increasingly powerful, they still fall short of the capabilities of dedicated servers. Processing very large datasets of tens or hundreds of gigabytes on the client-side can still be challenging and may degrade the user experience. DuckDB-Wasm is extremely efficient, but it cannot override the laws of physics.
Security is another critical aspect. Direct access to data from S3 means that credentials must somehow reach the client-side. This poses significant security risks if not handled properly. Mechanisms such as temporary, limited-scope tokens (e.g., AWS STS) are needed to ensure that users can only access the data they are authorized to, and that the tokens are short-lived. Additionally, correct configuration of CORS (Cross-Origin Resource Sharing) policies on S3 buckets is essential for secure operation.
Implementation Advice: Use temporary, role-based access tokens (e.g., AWS Security Token Service) for client-side authentication. This minimizes security risks as the tokens are only valid for a limited time and provide access only to the necessary resources.
Finally, current WebAssembly implementations are mostly single-threaded, meaning they cannot fully leverage the parallel processing capabilities of modern multi-core processors. Although future Wasm standards are likely to improve on this, it can currently limit the performance of very compute-intensive queries compared to systems running on dedicated, multi-core servers.
Implementation Strategies: How to Get Started in Practice
Introducing this technology into an organization can be done in several steps, starting with smaller, less critical projects. A good first step could be to create an internal-use analytical dashboard. This allows developers to familiarize themselves with the technology, assess its performance, and identify potential pitfalls in a low-risk environment. The goal could be to replace an existing, server-intensive report with a fully client-side solution.
The next level is client-side, embedded analytics. If a company offers a SaaS product, it can embed such a browser-based analytics module into its product, allowing customers to explore their own data without the company having to maintain an expensive, multi-tenant analytics infrastructure. This can be a significant competitive advantage, as users get more control and deeper insights.
The most advanced application area is the visualization of results generated by complex, interactive data applications and data processing AI agents. Here, the browser-based approach allows users not just to passively consume AI-generated insights, but to actively interact with the underlying data, validate the results, and ask new questions. Successfully implementing such projects often requires custom automation solutions to integrate data pipelines and the user interface. This level of integration allows the browser to truly become the central platform for data analysis.
Conclusion: The Browser as the Next-Generation Data Platform
The integration of DuckDB-Wasm and Apache Iceberg is not just an incremental improvement, but a fundamental paradigm shift in data access and processing. By bringing high-performance analytical capabilities directly into the browser, it eliminates many of the limitations and costs of traditional data architectures. This serverless, client-side approach offers unprecedented flexibility, scalability, and interactivity, democratizing big data analytics for a wider range of developers and users.
In the future, we will see more and more applications that leverage this model, especially in the field of AI-driven systems. The effectiveness of data processing AI agents will be multiplied when the results they generate can be explored by users instantly, without delay, through an interactive interface. As browsers and client-side hardware continue to grow stronger, the browser is increasingly likely to become the primary platform for enterprise data analysis. This transformation presents new challenges, but also huge opportunities for companies that are ready to rethink their data strategy and harness the untapped power of the browser.
Are you ready to harness the power of modern data analytics and artificial intelligence? Discover how our data processing AI agents can help optimize your business processes.
Explore Our Data Processing Solutions[Article generated by AiSolve AI Content System]
Frequently Asked Questions
What is DuckDB-Wasm?
DuckDB-Wasm is the version of the DuckDB analytical database engine compiled to WebAssembly. This allows the entire database engine to run directly in the web browser at near-native speed. With it, complex SQL queries and data processing tasks can be performed on the client-side without any server infrastructure.
What are the benefits of serverless browser-based analytics?
The main benefits are drastically lower costs (no need for server-side computation), infinite scalability (each user uses their own resources), increased interactivity (no network latency during queries), and a simplified architecture, which allows for faster development.
What are the limitations of this technology?
The main limitations are the browser's memory and processor capacity, which limits the size of the data that can be processed. In addition, security (handling credentials on the client-side) and the current single-threaded WebAssembly execution can be challenging, limiting parallelization on multi-core processors.
How does this relate to data processing AI agents?
Data processing AI agents can analyze huge amounts of data in the background and save the results into Iceberg tables. DuckDB-Wasm technology allows users to directly and interactively explore this AI-generated data through a web interface, without needing server-side computation for every interaction. This creates a much more dynamic and responsive user experience.
Készen állsz a saját weboldaladra?
Ingyenes konzultáció során átbeszéljük, hogyan segíthetünk vállalkozásodnak növekedni egy modern, gyors és konverzióoptimalizált weboldallal. 14 nap alatt kész, 0 Ft induló költséggel.





