
A modern vállalkozások működését az adatok mozgatják, de ezeknek az adatoknak az elérése, feldolgozása és elemzése hagyományosan költséges és bonyolult infrastruktúrát igényelt. Képzeljünk el egy világot, ahol a petabájtos adatkészletek elemzéséhez nincs szükségünk másra, csak egy webböngészőre. Ez a vízió most valósággá vált a DuckDB legújabb fejlesztésének köszönhetően, amely lehetővé teszi a közvetlen interakciót az Apache Iceberg adatkatalógusokkal a böngészőből. Ez a technológiai áttörés nem csupán egy technikai kuriózum, hanem alapjaiban változtathatja meg, hogyan gondolkodunk az adatelérésről, és hogyan működnek a jövőbeli adatfeldolgozó AI ügynökök. Az InfoQ friss jelentése szerint a DuckDB-Wasm, a DuckDB WebAssembly portja, mostantól lehetővé teszi a szerver nélküli adatinterakciót, ami a fejlesztők és adatelemzők számára eddig elképzelhetetlen rugalmasságot biztosít.
Ez a forradalmi megközelítés megszünteti a közvetítő rétegeket – a backend API-kat, az adat-proxykat és a komplex hitelesítési folyamatokat –, amelyek eddig elengedhetetlenek voltak a böngésző és a nagyméretű adattárolók, mint az S3, közötti kommunikációhoz. A felhasználók mostantól közvetlenül a böngészőjükből futtathatnak SQL lekérdezéseket hatalmas Iceberg táblákon anélkül, hogy egyetlen szervert is be kellene állítaniuk. Ez a paradigma-váltás drámaian csökkenti a belépési korlátot a big data analitika világába, és új lehetőségeket nyit meg az interaktív, valós idejű adatvizualizációs eszközök és a komplexebb, felhasználói oldali analitikai alkalmazások előtt. A cikkünkben mélyrehatóan elemezzük e technológia működését, üzleti előnyeit, a benne rejlő kihívásokat, és megvizsgáljuk, hogyan formálja át az adatvezérelt megoldások, különösen az adatfeldolgozó AI ügynökök fejlesztését.
| Terület / Area | Kulcsfontosságú Megállapítás / Key Insight |
|---|---|
| Szerver Nélküli Hozzáférés | A DuckDB-Wasm lehetővé teszi a közvetlen, böngésző alapú SQL lekérdezéseket Apache Iceberg táblákon, eliminálva a szerveroldali infrastruktúra szükségességét. |
| Költséghatékonyság | A közvetítő rétegek (API-k, proxy-k) kiiktatása drasztikusan csökkenti a fejlesztési, üzemeltetési és számítási költségeket. |
| Adatdemokratizáció | Az adatokhoz való hozzáférés egyszerűsödik, lehetővé téve, hogy több felhasználó (elemzők, fejlesztők) közvetlenül interakcióba lépjen a big data rendszerekkel. |
| AI Integráció | Ez a technológia új utakat nyit az adatfeldolgozó AI ügynökök számára, amelyek hatékonyabban tudnak adatokat szolgáltatni a felhasználói felületeken. |
| Felhasználói Élmény | Lehetővé válik a rendkívül interaktív, valós idejű adatvizualizációs és analitikai alkalmazások fejlesztése, amelyek közvetlenül a böngészőben futnak. |
A Szerver Nélküli Adatanalitika Új Hajnala
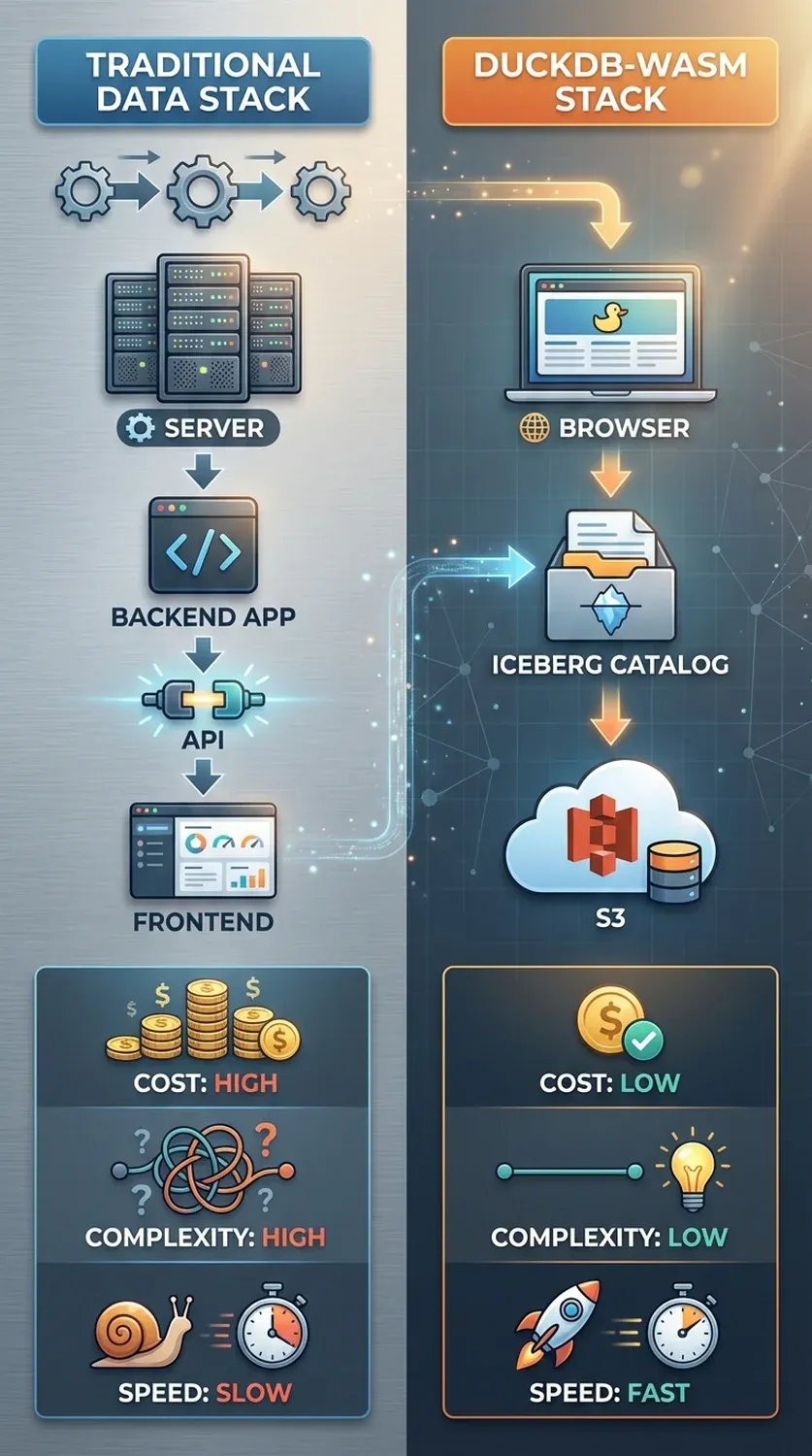
Az adatvezérelt döntéshozatal korában a vállalkozások számára a legnagyobb kihívást gyakran nem is az adatok gyűjtése, hanem azok hatékony és gyors elérése jelenti. A hagyományos adatarchitektúrák több rétegből állnak: az adatok egy adattóban vagy adattárházban helyezkednek el, egy backend alkalmazás felelős a lekérdezésükért, egy API szolgáltatja az eredményeket, és végül egy frontend alkalmazás jeleníti meg azokat a felhasználó számára. Minden egyes réteg komplexitást, késleltetést és költségeket ad a folyamathoz. A DuckDB és az Apache Iceberg böngésző alapú integrációja ezt a modellt borítja fel teljesen. Azáltal, hogy a lekérdezési logikát a kliens oldalra, azaz a felhasználó böngészőjébe helyezi át, egy radikálisan egyszerűsített, szerver nélküli architektúrát hoz létre.
Ez a megközelítés a „számítás az adatok közelébe vitele” elvét egy teljesen új szintre emeli. Ahelyett, hogy hatalmas adatmennyiséget mozgatnánk a hálózaton keresztül egy központi szerverre feldolgozásra, a böngésző maga válik egy mini-adatfeldolgozó központtá. Csak a szükséges adatokat tölti le közvetlenül az S3-kompatibilis tárolóból, és a feldolgozást helyben végzi el. Ez nemcsak a hálózati forgalmat és a szerverterhelést csökkenti, hanem páratlan interaktivitást is biztosít. A felhasználók valós időben, késleltetés nélkül fedezhetik fel az adatokat, mintha azok a saját gépükön lennének. Ez az új korszak alapvetően változtatja meg az adatelemző eszközök és az intelligens rendszerek, például a fejlett adatfeldolgozó AI ügynökök által vezérelt alkalmazások fejlesztését.
A Technológiai Szent Háromság: DuckDB, WebAssembly és Apache Iceberg
Ahhoz, hogy megértsük ennek az innovációnak a jelentőségét, érdemes megvizsgálni a három kulcsfontosságú technológiát, amelyek lehetővé teszik ezt a varázslatot. Mindegyikük egy-egy fontos darabja a kirakósnak, és együttesen alkotnak egy rendkívül erős rendszert.
DuckDB: Az Analitika Svájci Bicskája
A DuckDB egy beágyazható, folyamatorientált (in-process) analitikai adatbázis-kezelő rendszer (OLAP). Gyakran az „analitika SQLite-jaként” emlegetik. Kifejezetten gyors és hatékony analitikai lekérdezések futtatására tervezték, anélkül, hogy egy külön szerverfolyamatot kellene futtatni. Kompakt, gyors és rendkívül hatékony, ami ideálissá teszi erőforrás-korlátozott környezetekben, mint amilyen egy böngésző.
WebAssembly (Wasm): Natív Sebesség a Weben
A WebAssembly egy bináris utasításformátum, amely lehetővé teszi a magas szintű nyelveken (mint a C++, Rust) írt kód futtatását a webböngészőkben, közel natív sebességgel. A DuckDB-Wasm a DuckDB motor Wasm-ra fordított változata. Ez teszi lehetővé, hogy a teljes, nagy teljesítményű analitikai adatbázis motor közvetlenül a böngésző JavaScript motorja mellett fusson, kihasználva a modern hardverek képességeit.
Apache Iceberg: A Megbízható Adattáblák Formátuma
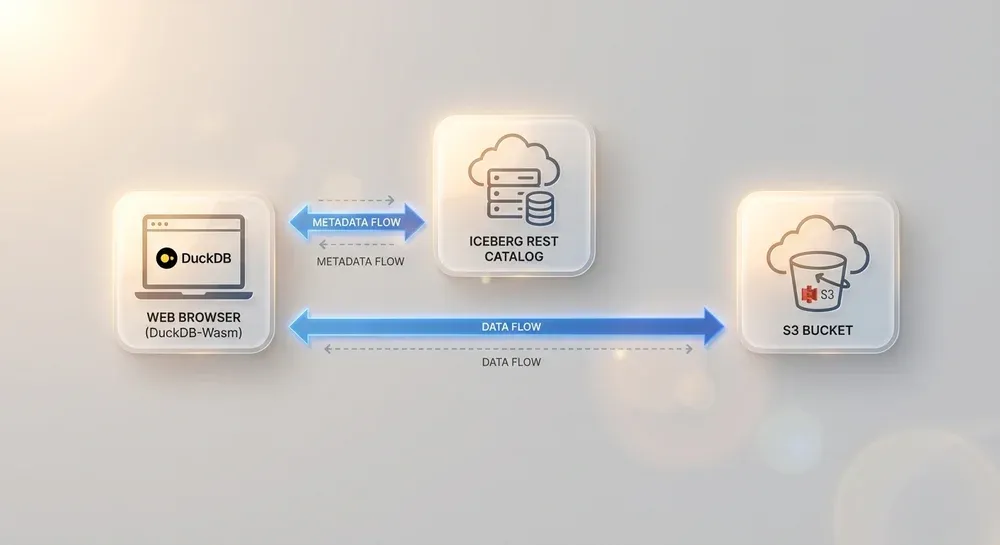
Az Apache Iceberg egy nyílt táblázat formátum, amelyet hatalmas analitikai adathalmazokhoz terveztek. Lényegében egy absztrakciós réteget képez a fájlok (pl. Parquet, ORC) felett, amely olyan adatbázis-szerű funkciókat biztosít, mint az ACID tranzakciók, az időutazás (time travel) és a séma evolúció, közvetlenül az adattavakon. Az Iceberg REST katalógus szolgáltatja a metaadatokat arról, hogy mely fájlok tartoznak egy adott táblához, lehetővé téve a DuckDB-Wasm számára, hogy pontosan tudja, mely adatokat kell letöltenie és feldolgoznia.
Hogyan Működik? A Böngésző, mint Adatbázis-Kliens
A folyamat elegánsan egyszerű, mégis rendkívül hatékony. Amikor egy felhasználó interakcióba lép egy ilyen webalkalmazással és lekérdezést indít, a következő lépések történnek a színfalak mögött, mindez a böngészőn belül:
- Lekérdezés Indítása: A felhasználó egy webes felületen keresztül elindít egy SQL lekérdezést (pl. egy diagramra kattint, vagy egy szűrőt állít be).
- Metaadatok Lekérése: A böngészőben futó DuckDB-Wasm kliens egy HTTP kérést küld az Iceberg REST katalógusnak. Ez a kérés a tábla metaadataira vonatkozik, nem a tényleges adatokra.
- Fájllista Fogadása: A katalógus válaszként visszaküldi azoknak a Parquet (vagy más formátumú) fájloknak a listáját és pontos helyét az S3-ban, amelyek a lekérdezés szempontjából relevánsak.
- Adatok Közvetlen Letöltése: A DuckDB-Wasm a böngésző beépített `fetch` API-jával, HTTP Range kérések segítségével, közvetlenül letölti a szükséges adatokat az S3-kompatibilis tárolóból. A Range kérések kulcsfontosságúak, mert lehetővé teszik, hogy csak a fájlok releváns részeit (pl. a szükséges oszlopokat vagy sorcsoportokat) töltse le, minimalizálva a hálózati forgalmat.
- Helyi Feldolgozás: Miután az adatok a böngésző memóriájába kerültek, a DuckDB-Wasm motor végrehajtja rajtuk a komplex SQL műveleteket (szűrés, aggregálás, csatolás) a felhasználó gépének processzorát használva.
- Eredmények Megjelenítése: Az eredményeket azonnal átadja a JavaScript rétegnek, amely frissíti a felhasználói felületet, például egy interaktív grafikont vagy táblázatot.
Ez a modell hatékonyan alakítja át a böngészőt egy vékony kliensből egy vastag, adatfeldolgozásra képes klienssé. Ez a képesség teszi lehetővé, hogy a háttérben működő, kifinomult adatfeldolgozó AI ügynökök eredményeit dinamikusan és interaktívan fedezhessék fel a felhasználók, anélkül, hogy minden egyes interakcióhoz szerveroldali számításra lenne szükség.
Az Üzleti Előnyök: Költségcsökkentés, Skálázhatóság és Demokratizált Adatelérés
A technológia vonzereje messze túlmutat a technikai elegancián; kézzelfogható üzleti előnyöket kínál a vállalatok számára. Az egyik legjelentősebb előny a költségek drasztikus csökkentése. A szerveroldali lekérdező motorok, API gateway-ek és a kapcsolódó infrastruktúra üzemeltetése jelentős kiadásokkal jár, mind a hardver, mind a humánerőforrás tekintetében. Ennek a tehernek a felhasználói oldalra történő áthelyezésével a számítási költségek gyakorlatilag nullára csökkennek, mivel a feldolgozást a felhasználók eszközei végzik. Ez különösen vonzóvá teszi az ad-hoc analitikai feladatokhoz és a prototípusok gyors elkészítéséhez.
Stratégiai tipp: Kezdje egy belső analitikai műszerfal prototípusának elkészítésével ezzel a technológiával. A fejlesztési sebesség és az alacsony költségek lehetővé teszik a gyors iterációt anélkül, hogy drága backend infrastruktúrába kellene fektetni.
A skálázhatóság egy másik kulcsfontosságú előny. A hagyományos rendszerekben a növekvő felhasználószám a szerverek terhelésének növekedését jelenti, ami vertikális vagy horizontális skálázást tesz szükségessé. Ezzel a szerver nélküli modellel a rendszer természetes módon skálázódik: minden új felhasználó a saját erőforrásait hozza magával. A rendszer annyi felhasználót képes kiszolgálni, ahányan csak csatlakoznak, anélkül, hogy a központi infrastruktúra túlterhelődne. Végül, ez a technológia demokratizálja az adatokhoz való hozzáférést. Azáltal, hogy eltávolítja a technikai akadályokat, szélesebb kör számára teszi lehetővé, hogy közvetlenül interakcióba lépjenek az adatokkal, anélkül, hogy az IT osztályra vagy adatmérnökökre kellene támaszkodniuk. Ez ösztönzi a felfedezést, a kísérletezést és végső soron egy adatvezéreltebb vállalati kultúra kialakulását.
A Jövő Felhasználói Felületei: Ahol az Adatfeldolgozó AI Ügynökök Munkája Láthatóvá Válik
Ez a böngésző alapú feldolgozási képesség tökéletesen illeszkedik az AI-vezérelt rendszerek, különösen az adatfeldolgozó AI ügynökök fejlődéséhez. Képzeljünk el egy olyan rendszert, ahol a háttérben futó AI modellek folyamatosan elemzik a beérkező adatokat, anomáliákat és mintázatokat keresnek, majd az eredményeket és a nyers adatokat egy Iceberg táblába írják. A felhasználók ezután egy webes felületen keresztül, a DuckDB-Wasm segítségével, rendkívül részletesen és interaktívan fedezhetik fel ezeket az eredményeket. Például egy marketingelemző valós időben szűrhet, csoportosíthat és vizualizálhat több milliárd sornyi kampányadatot, hogy megértse egy anomália okát, anélkül, hogy egyetlen szerveroldali lekérdezést indítana.
Itt válik kulcsfontosságúvá a professzionális weboldal készítés. Egy ilyen hatalmas, kliensoldali feldolgozási képesség kiaknázásához nem elegendő egy egyszerű weboldal. Olyan kifinomult, reszponzív és intuitív felhasználói felületekre van szükség, amelyek képesek kezelni a dinamikus adatvizualizációkat, a komplex szűrőket és az interaktív vezérlőket. A felhasználói élmény (UX) tervezése során figyelembe kell venni, hogy a felhasználó mostantól egy adatelemző eszköz teljes erejét birtokolja a böngészőjében. A hatékony weboldal készítés biztosítja, hogy ez az erő ne nyomasztó, hanem felhatalmazó legyen, lehetővé téve a felhasználók számára, hogy mélyebb betekintést nyerjenek az adataikba.
| Funkció | Hagyományos Webalkalmazás | DuckDB-Wasm alapú alkalmazás |
|---|---|---|
| Adatfeldolgozás helye | Központi szerver | Felhasználó böngészője |
| Interaktivitás | Magas késleltetés (hálózati körutak) | Azonnali, valós idejű |
| Infrastruktúra Költség | Magas (számítás, üzemeltetés) | Minimális (csak tárolás) |
| Skálázhatóság | Komplex, költséges | Automatikus, felhasználóval arányos |
| Backend Fejlesztés | Szükséges (API-k, adatlogika) | Gyakran elhagyható |
Kihívások és Korlátok: Mire Kell Figyelni a Böngésző Alapú Adatfeldolgozásnál?
Bár a böngésző alapú adatanalitika rendkívül ígéretes, fontos tisztában lenni a korlátaival is. Az egyik legnyilvánvalóbb kihívás a böngésző memória- és processzorkorlátja. Bár a modern böngészők és eszközök egyre erősebbek, még mindig elmaradnak a dedikált szerverek képességeitől. Nagyon nagy, több tíz vagy száz gigabájtos adathalmazok kliensoldali feldolgozása még mindig nehézségekbe ütközhet, és a felhasználói élmény rovására mehet. A DuckDB-Wasm rendkívül hatékony, de a fizika törvényeit nem tudja felülírni.
A biztonság egy másik kritikus szempont. Az adatokhoz való közvetlen hozzáférés az S3-ból azt jelenti, hogy a hitelesítő adatoknak (credentials) valamilyen formában el kell jutniuk a kliens oldalra. Ez komoly biztonsági kockázatokat vet fel, ha nem kezelik megfelelően. Olyan mechanizmusokra van szükség, mint az ideiglenes, korlátozott hatókörű tokenek (pl. AWS STS), hogy biztosítsák, a felhasználók csak a számukra engedélyezett adatokhoz férhessenek hozzá, és a tokenek rövid élettartamúak legyenek. Emellett a CORS (Cross-Origin Resource Sharing) policy-k helyes konfigurálása az S3 bucketeken elengedhetetlen a biztonságos működéshez.
Megvalósítási javaslat: Használjon ideiglenes, szerep-alapú hozzáférést biztosító tokeneket (pl. AWS Security Token Service) a kliensoldali hitelesítéshez. Ezzel minimalizálhatja a biztonsági kockázatokat, mivel a tokenek csak korlátozott ideig és csak a szükséges erőforrásokhoz adnak hozzáférést.
Végül, a jelenlegi WebAssembly implementációk többnyire egyszálúak, ami azt jelenti, hogy nem tudják teljes mértékben kihasználni a modern többmagos processzorok párhuzamos feldolgozási képességeit. Bár a jövőbeli Wasm szabványok valószínűleg javítani fognak ezen, ez jelenleg korlátozhatja a nagyon számításigényes lekérdezések teljesítményét a dedikált, többmagos szervereken futó rendszerekhez képest.
Implementációs Stratégiák: Hogyan Kezdjünk Hozzá a Gyakorlatban?
A technológia bevezetése egy szervezetben több lépésben történhet, kezdve a kisebb, kevésbé kritikus projektekkel. Egy jó első lépés lehet egy belső használatú analitikai műszerfal létrehozása. Ez lehetővé teszi a fejlesztők számára, hogy megismerkedjenek a technológiával, felmérjék a teljesítményét és azonosítsák a lehetséges buktatókat egy alacsony kockázatú környezetben. A cél lehet egy meglévő, szerverigényes riport kiváltása egy teljesen kliensoldali megoldással.
A következő szint az ügyféloldali, beágyazott analitika. Ha egy cég SaaS terméket kínál, beépíthet egy ilyen böngésző alapú analitikai modult a termékébe, lehetővé téve az ügyfelek számára, hogy a saját adataikat fedezzék fel anélkül, hogy a cégnek drága, több-bérlős (multi-tenant) analitikai infrastruktúrát kellene fenntartania. Ez jelentős versenyelőnyt jelenthet, mivel a felhasználók nagyobb kontrollt és mélyebb betekintést kapnak.
A legfejlettebb alkalmazási terület a komplex, interaktív adatalkalmazások és az adatfeldolgozó AI ügynökök által generált eredmények vizualizációja. Itt a böngésző alapú megközelítés lehetővé teszi a felhasználók számára, hogy ne csak passzívan fogyasszák az AI által generált betekintéseket, hanem aktívan interakcióba lépjenek az alapul szolgáló adatokkal, validálják az eredményeket és új kérdéseket tegyenek fel. Az ilyen projektek sikeres megvalósításához gyakran egyedi automatizálási megoldásokra van szükség az adatfolyamatok és a felhasználói felület integrálásához. Ez a szintű integráció teszi lehetővé, hogy a böngésző valóban az adatelemzés központi platformjává váljon.
Konklúzió: A Böngésző, mint a Következő Generációs Adatplatform
A DuckDB-Wasm és az Apache Iceberg integrációja nem csupán egy inkrementális fejlesztés, hanem egy alapvető paradigmaváltás az adatokhoz való hozzáférésben és azok feldolgozásában. Azáltal, hogy a nagy teljesítményű analitikai képességeket közvetlenül a böngészőbe helyezi, megszünteti a hagyományos adatarchitektúrák számos korlátját és költségét. Ez a szerver nélküli, kliensoldali megközelítés példátlan rugalmasságot, skálázhatóságot és interaktivitást kínál, demokratizálva a big data analitikát a fejlesztők és a felhasználók szélesebb köre számára.
A jövőben egyre több olyan alkalmazást láthatunk majd, amelyek kihasználják ezt a modellt, különösen az AI-vezérelt rendszerek területén. Az adatfeldolgozó AI ügynökök hatékonysága megsokszorozódik, ha az általuk generált eredményeket a felhasználók azonnal, késleltetés nélkül, egy interaktív felületen keresztül fedezhetik fel. Ahogy a böngészők és a kliensoldali hardverek tovább erősödnek, a böngésző egyre inkább a vállalati adatelemzés elsődleges platformjává válhat. Ez az átalakulás új kihívásokat, de egyben hatalmas lehetőségeket is teremt azoknak a vállalatoknak, amelyek készen állnak arra, hogy újragondolják adatstratégiájukat és kihasználják a böngészőben rejlő, eddig kiaknázatlan erőt.
Készen áll arra, hogy kihasználja a modern adatelemzésben és a mesterséges intelligenciában rejlő lehetőségeket? Fedezze fel, hogyan segíthetnek az adatfeldolgozó AI ügynökeink az Ön üzleti folyamatainak optimalizálásában.
Ismerje meg Adatfeldolgozó Megoldásainkat[Article generated by AiSolve AI Content System]
Gyakran Ismételt Kérdések
Mi az a DuckDB-Wasm?
A DuckDB-Wasm a DuckDB analitikai adatbázis-motor WebAssembly-re fordított változata. Ez lehetővé teszi a teljes adatbázis-motor futtatását közvetlenül a webböngészőben, közel natív sebességgel. Ennek segítségével komplex SQL lekérdezéseket és adatfeldolgozási feladatokat lehet elvégezni kliens oldalon, szerverinfrastruktúra nélkül.
Milyen előnyökkel jár a szerver nélküli böngésző alapú analitika?
A legfőbb előnyök a drasztikusan alacsonyabb költségek (nincs szükség szerveroldali számítási kapacitásra), a végtelen skálázhatóság (minden felhasználó a saját erőforrásait használja), a megnövelt interaktivitás (nincs hálózati késleltetés a lekérdezések során), és az egyszerűsített architektúra, ami gyorsabb fejlesztést tesz lehetővé.
Milyen korlátai vannak ennek a technológiának?
A fő korlátok a böngésző memória- és processzorkapacitása, ami behatárolja a feldolgozható adatok méretét. Emellett a biztonság (hitelesítő adatok kliensoldali kezelése) és a jelenlegi egyszálú WebAssembly futtatás is kihívást jelenthet, ami korlátozza a párhuzamosítást a többmagos processzorokon.
Hogyan kapcsolódik ez az adatfeldolgozó AI ügynökökhöz?
Az adatfeldolgozó AI ügynökök a háttérben képesek hatalmas adatmennyiséget elemezni és az eredményeket Iceberg táblákba menteni. A DuckDB-Wasm technológia lehetővé teszi, hogy a felhasználók egy webes felületen keresztül közvetlenül és interaktívan fedezzék fel ezeket az AI által generált adatokat, anélkül, hogy minden interakcióhoz szerveroldali számításra lenne szükség. Ez egy sokkal dinamikusabb és reszponzívabb felhasználói élményt teremt.
Készen állsz a saját weboldaladra?
Ingyenes konzultáció során átbeszéljük, hogyan segíthetünk vállalkozásodnak növekedni egy modern, gyors és konverzióoptimalizált weboldallal. 14 nap alatt kész, 0 Ft induló költséggel.





