
Key Takeaways
| Area / Terület | Key Insight / Kulcsfontosságú Megállapítás |
|---|---|
| Agentic Coding Speed | New models like Claude Code can approximate complex distributed systems that took human teams a year to develop, doing so in less than an hour, signaling a massive shift in development velocity. |
| Open-Source Competition | Open-source models like NousCoder-14B, trained in just four days, are matching or exceeding the performance of larger proprietary systems on standardized competitive programming benchmarks. |
| Data Scarcity Threat | Researchers are reaching the limits of high-quality, verifiable training data in specialized domains like competitive programming, necessitating a focus on synthetic data generation and self-play algorithms. |
| Learning Efficiency Gap | While AI models can rapidly achieve high performance (e.g., two years of human learning in 96 hours), they still require 24 times more training examples than human learners, highlighting a sample efficiency challenge. |
| Future of Testing | The next breakthrough in AI coding will involve multi-turn reinforcement learning, allowing models to use intermediate feedback (like compilation errors) to iteratively correct and improve their code. |
The Competition: Claude Code vs. NousCoder-14B and the Agentic Programming Revolution
The software development landscape is undergoing its most profound transformation since the adoption of version control systems. The recent simultaneous announcements of Anthropic’s proprietary Claude Code and Nous Research's open-source NousCoder-14B model have defined the custom automation solutions frontier for 2026. The shift is moving from simple code completion toward 'agentic programming,' where AI tools can independently conceptualize, write, debug, and iterate on complex software systems based on high-level natural language prompts. This transition is critical for enterprises seeking to accelerate development cycles and deploy sophisticated systems rapidly.
Anthropic's Claude Code has captivated the industry with demonstrations of its end-to-end development capabilities. A principal engineer at Google reported that Claude Code approximated a distributed agent orchestration system that took her human team a year to build, doing so from a mere three-paragraph prompt. This capability—approximating year-long projects in an hour—is not just an efficiency gain; it fundamentally changes the economic equation of software delivery and forms the ultimate goal of data processing AI agents. Such tools blur the line between concept and executable code, threatening to displace traditional engineering bottlenecks.
Against this backdrop of proprietary prowess, Nous Research has made a compelling case for radical openness. Their NousCoder-14B model, trained over four days using 48 NVIDIA B200 GPUs, demonstrates that open-source alternatives can not only compete but in some verifiable benchmarks, match or exceed larger proprietary systems. Achieving a 67.87 percent accuracy rate on the LiveCodeBench v6, this model sets a high bar for transparency, releasing the weights, the complete reinforcement learning environment, and the training harness. This fierce competition confirms that AI-assisted coding is rapidly maturing into a foundational technology, driving rapid evolution in the provision of custom automation solutions across every sector.
Strategic Insight: When evaluating agentic coding tools, prioritize solutions that offer both "one-shot" generation speed and transparent iteration capabilities, as real-world enterprise software requires continuous debugging and feedback loops, not just initial drafts.
The Need for Open Infrastructure in Software AI
The radical openness of NousCoder-14B, which includes the entire Atropos training stack, serves a purpose beyond mere philosophy. It provides the necessary infrastructure for reproducible research, allowing the academic and open-source communities to build upon established, verifiable work. This infrastructure is vital for establishing trust and auditing mechanisms in AI-generated code. As enterprises integrate AI into their core development pipelines, the ability to replicate and extend the underlying model becomes as important as its raw performance, particularly for security-critical applications or internal facing services deployed via a professionally developed website development dashboard.
The Technical Path of NousCoder-14B: Verifiable Rewards and DAPO
Achieving high performance in competitive programming is a complex reasoning challenge that requires highly structured training. NousCoder-14B relies on reinforcement learning (RL) guided by what researchers call “verifiable rewards.” In this system, the model generates a code solution which is then executed against hundreds of test cases within a sandboxed environment (using platforms like Modal). The model receives a simple, unambiguous binary signal: correct or incorrect. This mechanism ensures that the feedback loop is grounded in execution integrity, a requirement far more stringent than natural language tasks.
Executing this feedback loop at scale demands significant infrastructural sophistication. The training process involved verifying 24,000 problems, each with numerous test cases, under strict time (15 seconds) and memory (4GB) constraints. To maximize the utilization of their expensive 48-GPU cluster, Nous Research employed pipelining—overlapping the inference (code generation) and verification stages. As soon as the model generated one solution, it moved to the next problem while the first was checked asynchronously. This optimization is crucial in making the creation of these complex custom automation solutions economically viable.
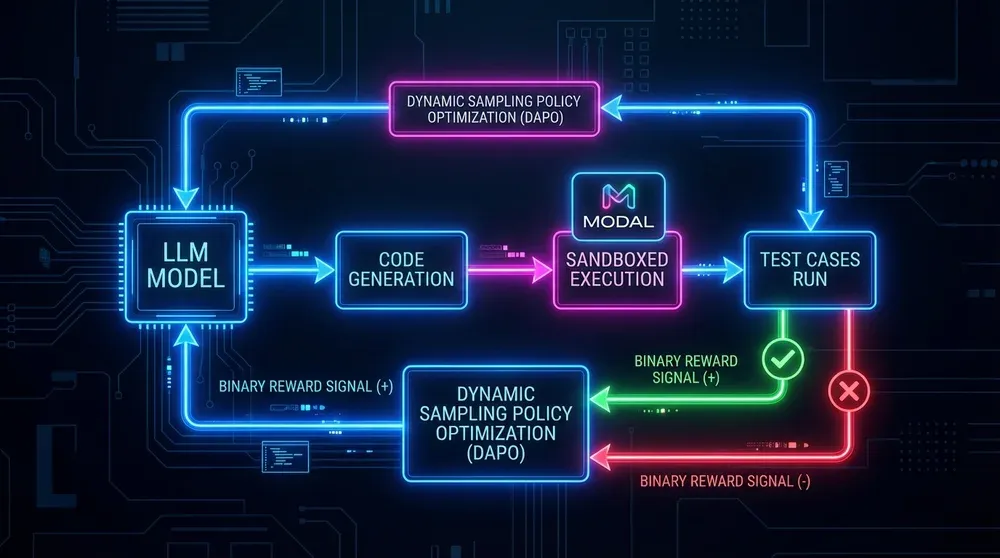
Figure: The Verifiable Reward Loop in Competitive AI Coding
A key algorithmic innovation was the use of Dynamic Sampling Policy Optimization (DAPO). This technique involves dynamically discarding training examples that provide no useful learning signal, specifically problems the model consistently solves or consistently fails. By focusing only on the "edge" cases—where the model has a 10% to 90% chance of success—researchers accelerate the learning curve. Furthermore, they used iterative context extension, starting training with a 32,000-token window and later expanding to 40,000 tokens, which, when extended to 80,000 tokens during evaluation, produced the best accuracy.
Implementation Advice: When deploying sophisticated RAG AI chatbot technology or coding agents, ensure your infrastructure supports parallel, sandboxed execution environments to enable rapid, verifiable testing and iteration, mimicking the DAPO strategy.
The Infrastructure Gap: Proprietary vs. Open-Source Compute
The ability to train a model like NousCoder-14B in four days relies on vast, modern compute resources (48 B200 GPUs). This highlights a growing infrastructure gap. While open-source research makes the *model* transparent, accessing the necessary compute to reproduce or extend the work remains a significant barrier for most organizations. Companies leveraging this technology must plan for massive scaling, whether through cloud providers or specialized compute partners, to fully utilize the potential of next-generation AI, including voice-first applications built on models like GPT-5.1, such as the companion developed by Tolan, which requires low-latency, real-time context reconstruction.
Simulated Evolution: How AI Reduced Two Years to 96 Hours
One of the most striking findings in the NousCoder-14B technical report is the comparison between human learning and machine learning in the competitive programming domain. The model's primary researcher, Joe Li, calculated that the model's performance improvement—climbing from a 1600-level rating to a 2100-2200 rating on platforms like Codeforces—mirrored a developmental leap that took him nearly two years of sustained practice during his adolescence. The AI achieved this equivalent intellectual evolution in just 96 hours of dedicated training. This acceleration showcases the unprecedented efficiency gains available through highly specialized RL frameworks for building data processing AI agents.
The juxtaposition is instructive: where human learning is marked by slow, sample-efficient experience (Li solved roughly 1,000 problems in two years), machine learning is defined by massive parallelism and data consumption. To achieve its 96-hour leap, the model required 24,000 distinct programming problems. Humans, therefore, remain dramatically more sample-efficient learners, capable of generalizing from minimal examples. This difference underscores a core challenge for AI: how to reduce the reliance on enormous datasets without sacrificing the dramatic speed gains achieved in fields like code generation, especially for enterprise-specific AI phone customer service systems where high-quality training data is often scarce.
| Metric | Human Programmer (Joe Li) | NousCoder-14B AI Model |
|---|---|---|
| Performance Leap (Codeforces Rating) | 1600 to 2100+ | 1600 to 2100+ |
| Time to Achieve Leap | Approximately 2 years | 96 hours (4 days) |
| Training/Learning Problems Required | ~1,000 Problems | 24,000 Problems |
| Sample Efficiency (Problems/Time Unit) | High (Learns more from each example) | Low (Requires massive data throughput) |
The core message for businesses is not that AI is replacing humans, but that it is fundamentally changing the nature of expertise. AI agents excel at pattern recognition across vast datasets, allowing for rapid knowledge compression. Humans, meanwhile, maintain the advantage in creative problem generation and generalization from minimal data. Successful integration of AI coding agents into corporate workflows means leveraging the machine for speed and pattern-solving, freeing up human developers to focus on architectural design, domain-specific nuance, and creative strategic planning. This partnership creates new avenues for custom automation solutions that were previously too complex or time-consuming to pursue.
Reaching the Data Plateau: Why AI Coding Progress Might Slow Down?
A significant concern highlighted in the Nous Research technical report, one that has implications across the entire generative AI industry, is the looming data scarcity. The training dataset for NousCoder-14B encompasses "a significant portion of all readily available, verifiable competitive programming problems." The researchers estimated that the 24,000 problems used are roughly the same order of magnitude as the total number of quality competitive programming problems accessible on the internet. This suggests that for this specialized, high-integrity domain, we are rapidly approaching the limits of high-quality training data.
This observation echoes a wider industry worry: while compute power continues its rapid, predictable growth (as exemplified by NVIDIA's B200 GPUs and the continuous scaling of infrastructure), high-quality training data is finite. For coding models, this issue is particularly acute because code requires automatic verification against known correct solutions. Unlike language models, where human proxies or general metrics can suffice, code either works or fails. This requirement makes the generation of synthetic data for this domain considerably more challenging, but also critically important for the future of building robust custom automation solutions.

Figure: The Growing Gap Between Compute Power and High-Quality Training Data Availability
The implication is clear: future AI development must pivot from relying solely on brute-force scaling of data and compute toward more data-efficient algorithms and architectural innovations. The challenge, according to Li, is that the most important research must now focus on synthetic data generation and improving sample-efficient learning. Without a new methodology to create verifiable training data, the exponential performance gains seen in agentic programming over the past year may plateau, hindering the complexity and reliability of future enterprise implementations.
Pro Tip: When designing your professional website creation strategy for AI tools, incorporate mechanisms for continuous, real-time feedback loops from user interactions. This proprietary feedback data can become your unique, high-quality synthetic training resource, countering industry-wide data scarcity.
The Blueprint for Next-Generation Coding Models: Multi-Turn and Self-Play
The next frontier for AI coding tools lies in making them truly agentic—capable of complex, sustained interaction and learning. Current models like NousCoder-14B primarily operate on a final binary reward (pass or fail). However, competitive programming and real-world software development are inherently iterative. Developers use intermediate feedback: compilation errors, incorrect outputs from public tests, or time limit violations. Researchers propose that multi-turn reinforcement learning, which trains models to incorporate this intermediate feedback across multiple attempts, could drastically improve performance and lead to more robust custom automation solutions.
Another ambitious direction proposed to combat data scarcity is "problem generation and self-play." This involves training models not only to solve programming problems but also to generate new, verifiable, and challenging problems for themselves. This self-curating curriculum, similar to techniques used successfully in game-playing AI like AlphaGo, would address the data constraint directly by creating an infinite loop of training material. While human programmers are currently far better at generating creative and useful problems, closing this "creativity gap" is the key to achieving exponential, self-sustained AI progress. This capacity is also being explored in other modalities, such as the real-time context reconstruction and memory-driven personalities of voice-first AIs like Tolan’s GPT-5.1 companion.
For businesses, this shift to multi-turn learning translates into practical demands for deployment interfaces. A simple prompt window is no longer sufficient; enterprises need sophisticated professional website creation dashboards and platforms that facilitate continuous monitoring, provide detailed error logs, and allow human oversight over the AI's iterative processes. The UI must be an integral part of the agent's feedback loop, ensuring safety and compliance as the AI iterates on critical infrastructure code.
| Development Stage | Current One-Shot AI | Future Multi-Turn AI |
|---|---|---|
| Feedback Utilization | Only uses final success/fail (Binary Reward) | Uses compilation errors, test failures (Intermediate Rewards) |
| Code Iteration | Single attempt or multiple distinct, unrelated attempts | Sequential, corrective iteration based on past failures |
| Data Source | Finite, pre-existing external datasets | Infinite, self-generated problems (Self-Play) |
Risks and Limitations: Agentic Focus vs. One-Shot Code Generation
Despite the impressive benchmarks, skepticism surrounds the practical application of AI coding agents, particularly regarding the distinction between academic performance and real-world software delivery. A crucial question is whether models like NousCoder-14B are merely optimized for "one-shot" competitive programming problems—where the entire context is provided upfront and a single correct solution is expected—or if they possess genuine "agentic focus" necessary for complex, multi-faceted software development. Real-world engineering requires iteration, context switching, understanding legacy systems, and negotiating complex dependencies.
Another identified limitation is the challenge of controlling response length. Researchers noted that incorrect solutions tended to be longer than correct ones, and code length quickly saturated available context windows during training. This issue, which algorithmic modifications failed to resolve, speaks to a fundamental difficulty in managing the output verbosity and efficiency of generative models when tasked with producing highly constrained, functional output like code. The need for conciseness and logical precision is paramount for robust data processing AI agents.

Enterprises must proceed with caution, recognizing that benchmark performance does not automatically translate to reliable production deployment. The failure of the AI assistant rollout in Alaskan courts, which took significantly longer than planned and required a reduction in original objectives, serves as a stark reminder that integration complexity often exceeds raw model capability. Deploying mission-critical custom automation solutions requires robust governance, meticulous human oversight, and a phased rollout strategy, especially when dealing with open-source tools that require substantial internal expertise to manage and secure.
Deployment Strategy: Focus initial AI coding agent deployments on well-defined, sandboxed tasks such as unit test generation, boilerplate code scaffolding, or API wrappers, before attempting end-to-end software development, mitigating the risk associated with complex agentic failures.
The Business Impact: Integrating AI-Generated Software
The rise of sophisticated AI coding agents fundamentally shifts competitive advantage. Companies that master the integration of these tools will gain exponential speed in internal tool development, rapid prototyping, and the creation of highly specialized custom automation solutions. For example, a major factor in the success of technologies like the voice-first AI companion by Tolan (built on GPT-5.1) is the ability to rapidly develop and refine the underlying code that handles low-latency responses and context reconstruction.
Beyond software, the principles of agentic AI are rapidly spreading to the physical world. The announcement of Boston Dynamics' Atlas robot partnership with Google DeepMind, and Caterpillar's use of NVIDIA Jetson Thor for edge AI on jobsites, shows a universal trend toward autonomous agents. For businesses, this means the software agents developing code for internal systems are operating under the same paradigm as the AI governing heavy machinery or interacting with customers via AI phone customer service. The core requirement is robust, verifiable code, whether it controls a line of text or a robotic arm.
The financial backing of companies like xAI, which recently raised $20 billion, underscores the massive strategic value placed on this technology by investors. This capital fuels the race for superior generative models. Enterprises cannot afford to wait for the proprietary dust to settle; they must begin experimenting now with open-source solutions like NousCoder-14B, which provide a low-cost entry point into understanding RL-based code generation. Successful integration requires defining clear governance frameworks and integrating the resulting code into existing DevOps pipelines, often managed via a custom website development dashboard that acts as the control plane for these autonomous systems.
Strategic Guide for Enterprises: How to Start Deploying AI Coding Agents
The journey toward leveraging AI coding agents for enterprise benefit is complex but mandatory. Organizations should adopt a multi-phased strategy that balances the immediate gains from proprietary tools (like Claude Code) with the long-term transparency and customizability of open-source models (like NousCoder-14B). The starting point is always a robust, sandboxed environment where code integrity and security can be verified before integration into mission-critical systems.
First, define a narrow scope. Instead of asking an agent to build a whole application, task it with generating the database schema, writing unit tests for existing modules, or creating specialized API wrappers. These low-risk, high-value tasks provide immediate returns and generate the verifiable feedback data necessary to train the next iteration of your internal agents. Second, invest in data expertise. The future competitive edge will lie not in purchasing the largest model, but in creating the highest-quality, domain-specific training data. This includes meticulously labeling and verifying internal codebases for fine-tuning open-source models.
Finally, remember that the interface matters. A coding agent is only as effective as the environment in which it operates. Designing a custom UI/UX via professional website development is essential for managing the multi-turn feedback loops, displaying error logs clearly, and allowing human engineers to provide the crucial intermediate signals that next-generation models will rely on. The focus must be on augmenting the developer, not replacing them, by using these tools to eliminate repetitive, low-level coding tasks and accelerating the path to market for all custom automation solutions.
Frequently Asked Questions
What is "Agentic Programming" and how does it differ from traditional AI coding?
Agentic programming refers to AI tools that can autonomously plan, iterate, debug, and execute complex software development tasks based on high-level goals. Traditional AI coding focuses on 'one-shot' generation, such as simple code completion or single function writing. Agentic systems, like Claude Code, integrate a full feedback loop, allowing them to correct errors and approximate systems that take humans months or years to build, making them a true form of custom automation solution.
What is the "data plateau" and how does it affect AI coding models?
The data plateau describes the point where researchers have exhausted the available supply of high-quality, verifiable training data in specific domains, such as competitive programming. The NousCoder-14B training utilized a significant portion of this data. Since AI coding models require automatically verifiable solutions, the finite nature of this data threatens to slow down the exponential performance gains previously observed, demanding new research into synthetic data generation and data-efficient learning.
How can open-source models like NousCoder-14B compete with proprietary systems?
NousCoder-14B demonstrates competitive performance by leveraging sophisticated reinforcement learning techniques (like DAPO) and large-scale, optimized compute infrastructure (NVIDIA B200 GPUs). Its radical openness, including the complete training stack, allows rapid community iteration and verification, challenging the closed-source model's ability to maintain a technical lead solely through massive scale. This provides a customizable base for enterprises to build their own custom automation solutions internally.
Why is custom website development crucial for deploying AI coding agents?
Any complex AI system, including a coding agent, requires a robust user interface for effective governance, monitoring, and interaction. Custom website development provides the necessary dashboard to manage multi-turn feedback loops, visualize execution logs, provide human oversight, and integrate the agent's output seamlessly into existing enterprise workflows, ensuring the system remains secure and compliant as it iterates on code.
Recommended / Ajánlott
- Explore Custom Automation Solutions for Your Enterprise Workflows
- Learn About Professional Website and Dashboard Development for AI Systems
- How Agentic Principles Are Applied to Advanced RAG Chatbot Deployments
The convergence of open-source innovation and agentic capabilities is accelerating the creation of internal software at an unprecedented pace. Leverage this trend to overcome data scarcity and deployment bottlenecks.
Start Architecting Your Custom Automation Strategy Today[Article generated by AiSolve AI Content System]
Készen állsz a saját weboldaladra?
Ingyenes konzultáció során átbeszéljük, hogyan segíthetünk vállalkozásodnak növekedni egy modern, gyors és konverzióoptimalizált weboldallal. 14 nap alatt kész, 0 Ft induló költséggel.





