A big data világában az Apache Spark a de facto szabvány a nagyméretű adathalmazok elosztott feldolgozására. Az ereje azonban egyben a gyengesége is: a több száz konfigurációs paraméter manuális finomhangolása egy komplex, időigényes és gyakran frusztráló feladat, amely mély szakértelmet igényel. A Data+AI Summit 2023. október 26-i konferenciáján Hina Gandhi, a Berkeley AI Research (BAIR) Lab kutatója által bemutatott úttörő eredmények azonban egy új korszakot jeleznek. A kutatás rávilágított, hogyan képesek a Multi-Agent Reinforcement Learning (MARL) modellel hajtott autonóm AI ügynökök felszámolni ezt a komplexitást, és önállóan, emberi beavatkozás nélkül optimalizálni a Spark fürtöket a csúcsteljesítmény és a költséghatékonyság érdekében.
Ez a technológiai áttörés nem csupán egy inkrementális javulás; ez egy paradigmaváltás abban, ahogyan az adat-infrastruktúrák működéséről gondolkodunk. Elmozdulunk a statikus, ember által definiált szabályoktól egy dinamikus, öntanuló és önoptimalizáló rendszer felé. Ahelyett, hogy a mérnökök a `spark.executor.memory` vagy a `spark.sql.shuffle.partitions` paraméterekkel zsonglőrködnének, az AI ügynökök folyamatosan figyelik a rendszer metrikáit, és a valós idejű igényeknek megfelelően, proaktívan avatkoznak be. Ez a megközelítés nemcsak a teljesítményt maximalizálja, hanem a felhőalapú erőforrások pazarlását is minimalizálja, ami közvetlen és jelentős költségmegtakarítást eredményez.

A Big Data feldolgozás kihívása és a Spark optimalizálási dilemma
Az Apache Spark elképesztő képességekkel ruházza fel a szervezeteket a petabájtos adathalmazok feldolgozására, de ez az erő komoly felelősséggel jár. Egy tipikus Spark feladat (job) teljesítményét több száz konfigurációs paraméter befolyásolja, amelyek egymással is komplex kölcsönhatásban állnak. A memóriakezeléstől (`spark.driver.memory`) a párhuzamosságig (`spark.default.parallelism`) minden egyes beállítás drámai hatással lehet a futási időre és a felhasznált erőforrásokra.
A hagyományos optimalizálási folyamat egy végtelennek tűnő kísérletezés. A data engineer csapatok heteket, sőt hónapokat töltenek azzal, hogy különböző konfigurációkat tesztelnek, logokat elemeznek, és megpróbálják megtalálni az „arany középutat” egy adott feladathoz. Ez a folyamat nemcsak lassú és drága, de rendkívül törékeny is. Amint az adatok volumene, sűrűsége vagy a feldolgozási logika megváltozik, a korábban tökéletesnek hitt konfiguráció hirtelen alulteljesítővé válhat, és a ciklus kezdődik elölről.
A probléma gyökere az, hogy az optimális konfiguráció nem egy statikus állapot, hanem egy dinamikus célpont. A bemeneti adatok jellege, a futtatott lekérdezések komplexitása és a rendelkezésre álló hardveres erőforrások mind folyamatosan változnak. Egy ember számára lehetetlen ezt a sokdimenziós problémateret valós időben átlátni és kezelni. Itt lépnek a képbe az AI adatfeldolgozó ügynökök, amelyek pontosan erre a dinamikus, komplex környezetre lettek tervezve.
Mik azok az AI adatfeldolgozó ügynökök és miért van rájuk szükség?
Az AI adatfeldolgozó ügynökök olyan autonóm szoftverentitások, amelyek képesek érzékelni a digitális környezetüket, döntéseket hozni, és cselekvéseket végrehajtani egy adott cél elérése érdekében. Ahelyett, hogy merev, előre programozott utasításokat követnének, tanulási algoritmusokat – jelen esetben megerősítéses tanulást – használnak, hogy idővel javítsák a teljesítményüket. Gondoljunk rájuk úgy, mint egy tapasztalt, éjjel-nappal dolgozó data engineer csapatra, amely kizárólag a rendszer optimális működésére fókuszál.
A Spark kontextusában ezek az ügynökök a Spark fürtöt tekintik a környezetüknek. Folyamatosan „megfigyelik” a kulcsfontosságú metrikákat: CPU-kihasználtság, memóriahasználat, I/O műveletek, garbage collection idők, shuffle műveletek adatai stb. Ezen információk alapján „döntenek” arról, hogy mely konfigurációs paramétereket kell módosítani, majd „cselekszenek” a Spark API-n keresztül, dinamikusan alkalmazva ezeket a változtatásokat – akár egy már futó feladat közben is.
Miért van erre szükségünk? Mert a modern adat-architektúrák komplexitása meghaladta az emberi kognitív képességek határait. A felhőalapú, skálázódó rendszerek dinamizmusa olyan szintű agilitást követel meg, amire a manuális folyamatok egyszerűen képtelenek. A specializált AI ügynökök bevezetése nem luxus, hanem szükségszerűség a versenyképesség megőrzéséhez. Lehetővé teszik a szervezetek számára, hogy a legtöbbet hozzák ki a drága felhőinfrastruktúrájukból, miközben a mérnökeik az üzleti értéket teremtő feladatokra koncentrálhatnak.
Az alapvető innováció: Multi-Agent Reinforcement Learning (MARL) az Apache Sparkban
Az autonóm optimalizálás mögött meghúzódó intelligencia a Multi-Agent Reinforcement Learning (MARL), a gépi tanulás egy fejlett ága. Míg a hagyományos megerősítéses tanulás (RL) egyetlen ügynököt használ egy környezetben, a MARL több, egymással együttműködő (vagy versengő) ügynököt alkalmaz, ami tökéletesen illeszkedik az elosztott rendszerek, mint a Spark, természetéhez.
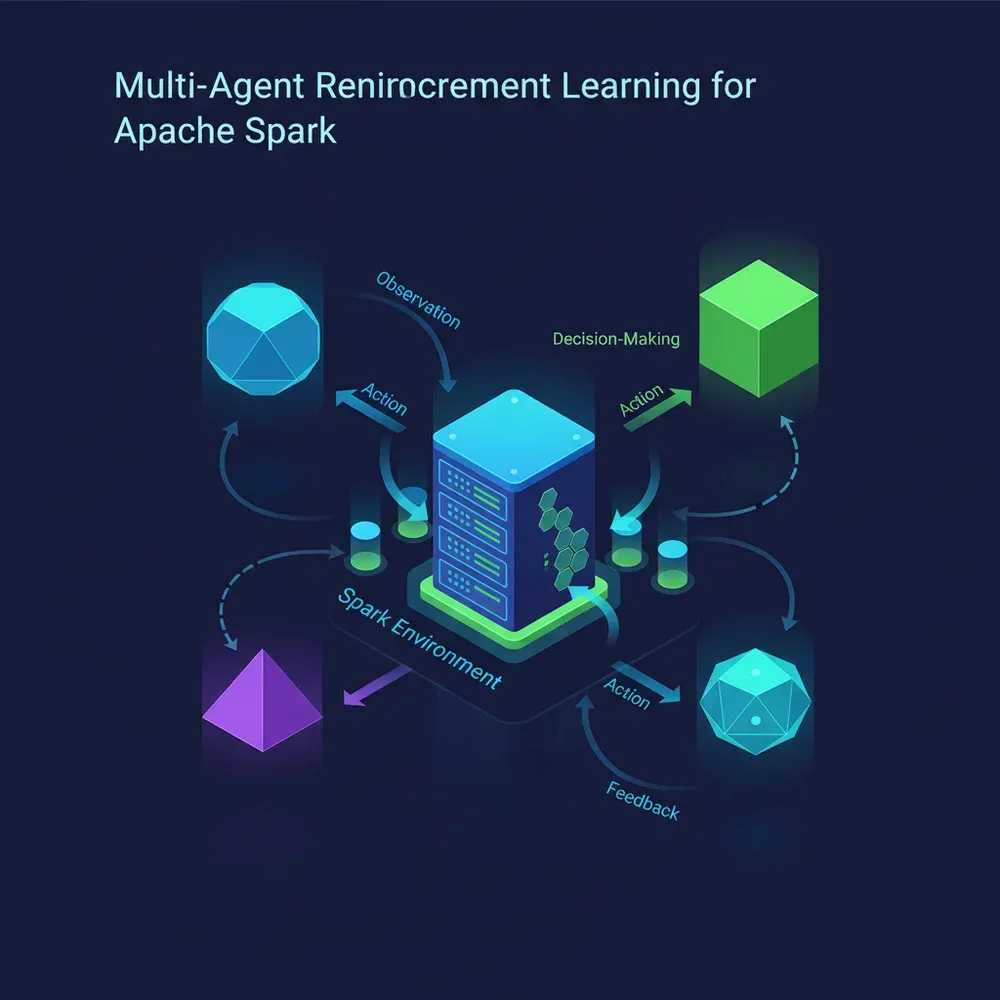
Képzeljük el, hogy minden Spark executor (a munkavégző csomópont) vagy akár minden főbb komponens (Driver, Executor, Shuffle Service) saját AI ügynököt kap. Ezek az ügynökök nemcsak a saját lokális állapotukat figyelik, hanem kommunikálnak is egymással, hogy egy globálisan optimális döntést hozzanak. Ez a decentralizált megközelítés sokkal robusztusabb és skálázhatóbb, mint egyetlen, mindentudó központi vezérlő.
A megerősítő tanulás alapjai az optimalizáláshoz
A megerősítéses tanulás a próba-szerencse elvén alapul, hasonlóan ahhoz, ahogyan egy ember tanul. A folyamat kulcselemei a Spark kontextusában:
- Ügynök (Agent): Az AI-modell, amely a döntéseket hozza (pl. egy neurális háló).
- Környezet (Environment): Az Apache Spark fürt és a rajta futó adatfeldolgozási feladat.
- Állapot (State): A környezet egy adott időpillanatban történő pillanatfelvétele. Ez egy vektor, amely tartalmazza a releváns metrikákat (pl. CPU terhelés, rendelkezésre álló memória, I/O várakozási idő, a feldolgozandó adatok mérete).
- Akció (Action): Az ügynök által végrehajtott művelet. Ez egy vagy több Spark konfigurációs paraméter módosítása (pl. növelje az executorok számát 10-ről 15-re, vagy csökkentse a shuffle partíciók számát 200-ról 100-ra).
- Jutalom (Reward): Egy numerikus érték, ami visszajelzést ad az ügönöknek az akciójának sikerességéről. A cél a hosszú távú kumulatív jutalom maximalizálása.
Például, ha egy ügynök akciója (a memória növelése) a feladat futási idejének csökkenéséhez vezet, pozitív jutalmat kap. Ha egy másik akció (a párhuzamosság drasztikus csökkentése) a feladat lelassulását okozza, negatív jutalmat (büntetést) kap. Az ügynök célja, hogy megtanulja azt a „politikát” (policy), amely az adott állapotokban a legmagasabb jutalommal kecsegtető akciókat választja.
Ügynök architektúra: Megfigyelők, Tanulók és Végrehajtók
Egy tipikus MARL rendszer a Sparkhoz három fő komponensből áll:
- Megfigyelők (Observers): Ezek a komponensek felelősek a Spark metrikák gyűjtéséért. Rákapcsolódnak a Spark UI-ra, a metrikarendszerekre (pl. Prometheus, Ganglia) és a log fájlokra, hogy nyers adatokat gyűjtsenek a fürt állapotáról.
- Tanulók (Learners): Ez a rendszer magja. A megfigyelőktől kapott állapotadatok és a korábbi akciókért kapott jutalmak alapján a tanuló (jellemzően egy elosztottan futó neurális háló) frissíti a döntéshozatali politikáját. Ez a tréning folyamatosan zajlik a háttérben.
- Végrehajtók (Actuators): Amikor a tanuló meghoz egy döntést (egy akciót), a végrehajtó felelős annak implementálásáért. Ez a komponens a Spark API-n vagy a fürtkezelőn (pl. YARN, Kubernetes) keresztül módosítja a szükséges konfigurációs paramétereket.
A környezet és a jutalomfüggvények szerepe
A jutalomfüggvény (reward function) a legkritikusabb eleme a rendszernek, mivel ez határozza meg, hogy mit jelent az „optimális” működés. A jutalomfüggvényt az üzleti célokhoz kell igazítani. Ez általában egy súlyozott kombinációja több célnak:
Példa Jutalomfüggvény:
`Reward = w1 * (1 / FutásiIdő) - w2 * (CPU_Kihasználtság * Ár) - w3 * (Memória_Kihasználtság * Ár)`
Itt `w1`, `w2`, és `w3` súlyok, amelyekkel az üzleti prioritásokat lehet beállítani. Ha a sebesség a legfontosabb, `w1` lesz a legnagyobb. Ha a költségcsökkentés a cél, `w2` és `w3` kap nagyobb hangsúlyt. Az ügynökök megtanulják, hogyan egyensúlyozzanak ezek között a gyakran egymásnak ellentmondó célok között, hogy a legjobb kompromisszumot érjék el.
Hogyan optimalizálják az AI ügynökök autonóm módon a Spark konfigurációkat?
Az autonóm optimalizálási folyamat egy folyamatos, zárt láncú ciklus, amely soha nem áll meg. Ahelyett, hogy egyszer beállítanánk a rendszert és reménykednénk a legjobbban, az AI ügynökök folyamatosan finomhangolják azt a változó körülményekhez igazodva.

Adatgyűjtés és jellemzőmérnökség a Spark metrikákból
Az első lépés a releváns adatok gyűjtése. Az ügynökök nemcsak az alapvető metrikákat (CPU, memória) figyelik, hanem a Spark-specifikus, mélyebb szintű információkat is:
- Stage és Task metrikák: Az egyes feldolgozási lépések (stage-ek) és feladatok (task-ok) futási ideje, adat-spill (memóriából diszkre írás), shuffle olvasási/írási méretek.
- Garbage Collection (GC) statisztikák: A GC futások gyakorisága és időtartama, ami a memórianyomás fontos indikátora.
- Executor állapotok: Az executorok hozzáadásának, eltávolításának és esetleges hibáinak naplózása.
- Adatforrás metrikák: A beolvasott és írt adatok mennyisége, a partíciók száma.
Ezekből a nyers adatokból a rendszer „jellemzőket” (features) képez, amelyek jobban leírják a rendszer állapotát. Például ahelyett, hogy csak a GC időt nézné, kiszámíthatja a „GC idő aránya a teljes futási időhöz képest”, ami egy sokkal informatívabb mutató.
Modelltréning és politikai tanulás a konfigurációs terekben
A begyűjtött és feldolgozott adatok alapján az AI modell (a „tanuló”) elkezdi feltérképezni a hatalmas konfigurációs teret. A modell célja, hogy megtanulja a kapcsolatot az állapotok, akciók és a kapott jutalmak között. Lényegében egy komplex függvényt tanul meg, amely megjósolja, hogy egy adott állapotban melyik akció fogja a legmagasabb jövőbeli jutalmat eredményezni.
A kezdeti fázisban az ügynökök többet „felfedeznek” (exploration), azaz véletlenszerűbb akciókat próbálnak ki, hogy minél több tapasztalatot gyűjtsenek a konfigurációs tér különböző részeiről. Idővel, ahogy a modell egyre magabiztosabbá válik, átvált a „kihasználás” (exploitation) fázisba, ahol már a tanult legjobb akciókat részesíti előnyben. Ez az exploration-exploitation dilemma a megerősítéses tanulás egyik alapvető koncepciója.
Dinamikus konfigurációbeállítás valós időben
A folyamat leglátványosabb része a valós idejű beavatkozás. Amikor a modell egy optimálisnak ítélt akciót választ, a végrehajtó komponens azonnal alkalmazza azt. A Spark modern verziói támogatják számos kulcsfontosságú paraméter dinamikus, futás közbeni módosítását. Ilyenek például:
- Dinamikus erőforrás-allokáció: Az ügynök növelheti vagy csökkentheti az executorok számát a terhelés függvényében. Ha egy feladat egy intenzív shuffle fázishoz ér, az ügynök több executort kérhet, majd a fázis végén felszabadíthatja őket.
- Adaptív Lekérdezés Végrehajtás (Adaptive Query Execution - AQE): Az ügynök befolyásolhatja az AQE döntéseit, például a shuffle partíciók számának futás közbeni optimalizálásával vagy a join stratégiák megváltoztatásával.
- Memóriakezelés: Az ügynök finomhangolhatja a memóriafoglalást az execution és a storage között, attól függően, hogy a feladat éppen számítás- vagy adatintenzív.
Ez a folyamatos visszacsatolási hurok – megfigyelés, döntés, cselekvés, jutalmazás – teszi lehetővé, hogy a rendszer önállóan alkalmazkodjon és javuljon, emberi felügyelet nélkül.
Kulcsfontosságú előnyök: Teljesítmény, költség és működési hatékonyság
Az autonóm Spark optimalizálás bevezetése nem csupán technikai érdekesség, hanem komoly üzleti előnyökkel jár. A hatások a szervezet szinte minden szintjén érezhetők, a pénzügyi kimutatásoktól a mérnökök napi munkájáig.
Adatátviteli sebesség gyorsítása és késleltetés csökkentése
A legközvetlenebb előny a teljesítménynövekedés. Azáltal, hogy a konfiguráció mindig az aktuális terheléshez van igazítva, az AI ügynökök megszüntetik a szűk keresztmetszeteket, amelyek a manuálisan beállított rendszereket sújtják. A Berkeley kutatása és más iparági esettanulmányok is azt mutatják, hogy a MARL-alapú optimalizálás akár 30-45%-kal is csökkentheti a Spark feladatok átlagos futási idejét. Ez gyorsabb adatelemzést, frissebb riportokat és alacsonyabb késleltetést jelent a valós idejű alkalmazások számára.
Jelentős költségmegtakarítás a felhőinfrastruktúrán
A felhőben a teljesítmény szorosan összefügg a költségekkel. A rövidebb futási idő kevesebb számítási erőforrás (vCPU-óra) felhasználását jelenti. Ennél is fontosabb, hogy az ügynökök intelligensen kezelik az erőforrásokat. Ahelyett, hogy egy teljes feladathoz a csúcsterhelésnek megfelelő, drága fürtöt tartanának fenn, dinamikusan skálázzák fel és le az erőforrásokat. Ez a „right-sizing” megakadályozza a pazarlást, ami a felhőköltségek egyik legnagyobb forrása. A tapasztalatok szerint a szervezetek akár 50-60%-os megtakarítást is elérhetnek a Spark-hoz kapcsolódó felhőköltségeiken. Ez a drága AI-infrastruktúra korában kulcsfontosságú versenyelőny.
Mérnöki erőforrások felszabadítása a stratégiai munkára
Talán a legértékesebb, bár nehezebben számszerűsíthető előny a humán tőke hatékonyabb kihasználása. A magasan képzett és drága data engineerek és DevOps szakemberek idejük jelentős részét töltik reaktív hibaelhárítással és a teljesítmény finomhangolásával. Az autonóm optimalizálás leveszi ezt a terhet a vállukról. Ahelyett, hogy konfigurációs fájlokban és logokban kutatnának, a mérnökök az üzleti logika fejlesztésére, új adatforrások integrálására és az adatokból nyert érték maximalizálására koncentrálhatnak. Ez nemcsak a termelékenységet növeli, hanem a munkavállalói elégedettséget is, hiszen a szakemberek a kreatív, magasabb hozzáadott értékű feladatokkal foglalkozhatnak.
Valós alkalmazások és felhasználási esetek
Az AI-vezérelt Spark optimalizálás nem elméleti koncepció; már ma is számos területen bizonyítja értékét, ahol a nagy adatmennyiség és a gyors feldolgozás kritikus fontosságú.

ETL pipeline-ok és adattárházak optimalizálása
Az Extract, Transform, Load (ETL) folyamatok a modern adatinfrastruktúrák gerincét képezik. Ezek a feladatok gyakran nagy, de változó méretű adatbatch-eket dolgoznak fel. Az AI ügynökök képesek felismerni, hogy egy adott napon kisebb vagy nagyobb adatmennyiség érkezett, és ennek megfelelően skálázni az erőforrásokat. Ezzel biztosítják, hogy az adattárházak mindig időben, a szolgáltatási szint megállapodásoknak (SLA) megfelelően frissüljenek, anélkül, hogy feleslegesen pazarolnák az erőforrásokat a csendesebb időszakokban.
Gépi tanulási modell tréning skálázása
A gépi tanulási modellek, különösen a mélytanulási modellek tréningje rendkívül számításigényes. A Sparkot gyakran használják a terabájtos tréning adathalmazok előfeldolgozására és a modelltréning elosztására. Az AI ügynökök itt kulcsfontosságúak a tréningidő minimalizálásában. Képesek optimalizálni az adatparticionálást és a memóriakezelést, hogy a GPU-k vagy más gyorsítók soha ne várakozzanak adatra, ezzel drasztikusan lerövidítve a modellfejlesztési ciklust.
Valós idejű analitika és stream feldolgozás
A Spark Streaming és a Structured Streaming lehetővé teszi a folyamatosan érkező adatok valós idejű feldolgozását. Az ilyen alkalmazásoknál (pl. csalásdetekció, valós idejű ajánlórendszerek) a késleltetés kritikus. Az AI ügynökök folyamatosan figyelik a bejövő adatáram sebességét és a feldolgozási lánc állapotát. Ha a rendszer kezd lemaradni, automatikusan több erőforrást allokálnak a késleltetés csökkentése érdekében, biztosítva a valós idejű adatfeldolgozás megbízhatóságát.
Kihívások és megfontolások a MARL bevezetésében a Sparkhoz
Bár a MARL-alapú optimalizálás hatalmas ígéretet rejt, a bevezetése nem triviális. A szervezeteknek tisztában kell lenniük a technikai és működési kihívásokkal, mielőtt belevágnának egy ilyen projektbe.
Elosztott RL rendszerek komplexitása
Egy MARL rendszer felépítése és karbantartása önmagában is egy komplex elosztott rendszermérnöki feladat. Szükség van egy robusztus metrikagyűjtő pipeline-ra, egy skálázható modelltréning infrastruktúrára és megbízható végrehajtó mechanizmusokra. A rendszernek hibatűrőnek kell lennie, és kezelnie kell az olyan helyzeteket, mint a hálózati problémák vagy a csomópontok kiesése.
Adatbiztonság és irányítás
Az optimalizáló ügynököknek mély hozzáférésre van szükségük a Spark fürt metrikáihoz és vezérlési síkjához. Ez biztonsági kérdéseket vet fel, különösen érzékeny adatokkal dolgozó környezetekben. Gondoskodni kell a megfelelő jogosultságkezelésről, auditálásról és arról, hogy az ügynökök ne férhessenek hozzá magukhoz az adatok tartalmához, csak a metaadatokhoz és a teljesítménymutatókhoz.
Integráció a meglévő infrastruktúrával
A legtöbb szervezet már rendelkezik kiforrott CI/CD pipeline-okkal, monitoring rendszerekkel (pl. Datadog, New Relic) és fürtkezelő eszközökkel (pl. Kubernetes, YARN). Az AI optimalizációs rendszert zökkenőmentesen kell integrálni ezekbe a meglévő eszközökbe, hogy ne hozzon létre egy újabb, izolált silót. Ez gondos tervezést és API-szintű integrációt igényel.
Szakértői betekintés: Mit mondanak az adatok a MARL-ről a Sparkban?
A technológia hatékonyságát a legjobban a pártatlan, tudományos kutatások és az iparági szakértők véleménye támasztja alá. A már említett, Hina Gandhi által a Data+AI Summit 2023 konferencián bemutatott eredmények mérföldkőnek számítanak ezen a területen.
Gandhi és csapata nem csupán a teljesítménynövekedést igazolta, hanem azt is kimutatták, hogy a MARL rendszer sokkal jobban alkalmazkodik a váratlan terhelésváltozásokhoz. Míg a statikus konfigurációk teljesítménye drasztikusan leromlott, amikor a lekérdezések vagy az adatok jellege megváltozott, az AI ügynökök néhány cikluson belül megtanulták az új mintázatot és újraoptimalizálták a rendszert. Ez a robusztusság és adaptivitás az, ami a technológiát igazán forradalmivá teszi.
Az autonóm adatfeldolgozás jövője: A Sparkon túl
Bár a jelenlegi fókusz az Apache Sparkon van, az autonóm, AI-vezérelt optimalizálás elvei sokkal szélesebb körben alkalmazhatók. Ez a technológia az egész adatinfrastruktúra-verem alapvető működését átalakíthatja.
A jövőben hasonló AI ügynökök optimalizálhatják az adatbázisokat (pl. indexek automatikus létrehozása és törlése), az üzenetküldő rendszereket (pl. Kafka partíciók és replikációs faktorok dinamikus beállítása), valamint a teljes felhőinfrastruktúrát (pl. a legköltséghatékonyabb virtuális gép típusok valós idejű kiválasztása). A végső cél egy teljesen autonóm, önvezető adatközpont, ahol az emberi operátorok magas szintű üzleti célokat határoznak meg, és az AI ügynökökből álló rendszer gondoskodik a célok leghatékonyabb megvalósításáról.
Ez a vízió egybecseng az autonóm adatfeldolgozó AI ügynökök vállalati stratégiákban betöltött egyre növekvő szerepével, ahol a cél a komplex rendszerek automatizálása és az emberi beavatkozás minimalizálása.
Készen áll a jövőálló adat infrastruktúrára?
Az AI-vezérelt optimalizálás már nem a távoli jövő. A technológia kiforrott, és a korai alkalmazók már most jelentős versenyelőnyre tesznek szert. A kérdés már nem az, hogy be kell-e vezetni az autonóm rendszereket, hanem az, hogy mikor és hogyan.
Azon AI mérnökök, adatarchitektusok és technológiai vezetők számára, akik a legtöbbet akarják kihozni a big data befektetéseikből, most van itt az idő cselekedni. A manuális finomhangolásra pazarolt minden egyes mérnökóra elvesztegetett lehetőség. Az autonóm optimalizálás bevezetése nemcsak a költségeket csökkenti és a teljesítményt növeli, hanem egy agilisabb, rugalmasabb és jövőállóbb adatinfrastruktúrát teremt.
Következtetés: Az önoptimalizáló adatrendszerek hajnala
Az Apache Spark manuális optimalizálásának kora a végéhez közeledik. A Multi-Agent Reinforcement Learning alapú AI ügynökök megjelenése egy új korszakot nyit az adatfeldolgozásban – az intelligens, autonóm és önoptimalizáló rendszerek korát. Ez a technológia nemcsak a Spark teljesítményét és költséghatékonyságát emeli új szintre, hanem alapjaiban változtatja meg a data engineer szakma szerepét is, felszabadítva a szakembereket a repetitív, alacsony értékű feladatok alól.
Ahogy Hina Gandhi kutatása is rávilágított, a kérdés már nem az, hogy az AI képes-e jobban kezelni a komplex rendszereket, mint az ember, hanem az, hogy a szervezetek milyen gyorsan képesek adaptálni ezt az átalakító erejű technológiát. Azok, akik most lépnek, a jövő nyertesei lesznek egy egyre inkább adatvezérelt világban.
Gyakran Ismételt Kérdések
Hogyan különbözik a MARL a hagyományos Spark optimalizálási technikáktól?
A hagyományos technikák (pl. manuális hangolás, heurisztikák) statikusak és reaktívak. Egy adott, ismert terhelésre optimalizálnak, és nem tudnak alkalmazkodni a változásokhoz. Ezzel szemben a MARL egy dinamikus, proaktív megközelítés. Az AI ügynökök folyamatosan tanulnak a valós idejű adatokból, és a rendszer állapotának változásával párhuzamosan, futás közben módosítják a konfigurációt, hogy mindig az aktuális céloknak (pl. sebesség, költség) leginkább megfelelő állapotban tartsák a rendszert.
Milyen előfeltételei vannak az AI adatfeldolgozó ügynökök bevezetésének a Sparkban?
A sikeres bevezetéshez három fő dolog szükséges: 1) Egy robusztus metrikagyűjtő rendszer, amely részletes, valós idejű adatokat szolgáltat a Spark fürt működéséről. 2) Egy modern Spark verzió, amely támogatja a kulcsfontosságú paraméterek dinamikus konfigurálását. 3) Egy platform vagy keretrendszer a megerősítéses tanulási modellek tréningjéhez és futtatásához, amely integrálható a meglévő infrastruktúrával.
Optimalizálhatják-e az AI ügynökök egyszerre a teljesítményt és a költségeket?
Igen, ez az egyik legnagyobb előnyük. A jutalomfüggvény (reward function) úgy definiálható, hogy mindkét célt figyelembe vegye. Például a jutalom növekedhet a sebességgel, de csökkenhet a felhasznált erőforrások költségével. Az ügynök megtanulja megtalálni az optimális egyensúlyt a két, gyakran ellentétes cél között, az üzleti prioritásoknak megfelelően. Ezt a súlyozást a rendszer operátorai finomhangolhatják.
Biztonságos-e a Multi-Agent Reinforcement Learning az érzékeny vállalati adatok számára?
Igen, a megfelelően implementált rendszerek biztonságosak. Az optimalizáló ügynököknek nincs szükségük hozzáférésre a feldolgozott adatok tartalmához. Kizárólag a rendszer metaadataival és teljesítménymetrikáival dolgoznak (pl. mennyi adatot írt egy task, mennyi ideig futott, mennyi memóriát használt). A megfelelő jogosultságkezeléssel (pl. IAM szerepkörök) biztosítható, hogy az ügynökök csak a működésükhöz elengedhetetlenül szükséges vezérlési és monitorozási API-kat érjék el.
Milyen szakértelem szükséges ezeknek az ügynököknek a telepítéséhez és kezeléséhez?
A bevezetéshez jellemzően egy multidiszciplináris csapatra van szükség, amelyben van data engineer (Spark szakértelemmel), MLOps/DevOps engineer (infrastruktúra és automatizálás), valamint egy gépi tanulási szakember (RL modellezés). Azonban egyre több menedzselt platform és szolgáltatás jelenik meg, amelyek célja, hogy absztrahálják a komplexitás nagy részét, és lehetővé tegyék a technológia egyszerűbb bevezetését anélkül, hogy egy teljes RL kutatócsapatot kellene felépíteni.
Mennyi idő alatt láthatók kézzelfogható eredmények az autonóm Spark optimalizálásból?
Az eredmények viszonylag gyorsan jelentkezhetnek. A kezdeti tréningfázis (amikor az ügynök felfedezi a környezetet) után, ami a feladatok komplexitásától függően néhány naptól egy-két hétig tarthat, a rendszer már elkezd intelligens döntéseket hozni. A legtöbb szervezet már az első hónapban látja a futási idők csökkenését és a költségmegtakarítást, ami az idő múlásával, ahogy az ügynök egyre több tapasztalatot gyűjt, tovább javul.
Melyek a lehetséges kockázatok vagy hátrányok az AI-ra való támaszkodásban a Spark konfigurációjában?
A fő kockázat a kontroll látszólagos elvesztése és a rendszer „fekete doboz” jellege. Fontos, hogy a rendszer rendelkezzen biztonsági korlátokkal (guardrails), amelyek megakadályozzák, hogy az ügynök extrém, a rendszer stabilitását veszélyeztető konfigurációkat alkalmazzon. Emellett elengedhetetlen a részletes monitorozás és naplózás, hogy az emberi operátorok mindig megérthessék, miért hozott egy adott döntést az AI. A kezdeti időkben érdemes lehet „árnyék módban” (shadow mode) futtatni a rendszert, ahol az ügynök javaslatokat tesz, de a végrehajtáshoz még emberi jóváhagyás szükséges.
Készen állsz a saját weboldaladra?
Ingyenes konzultáció során átbeszéljük, hogyan segíthetünk vállalkozásodnak növekedni egy modern, gyors és konverzióoptimalizált weboldallal. 14 nap alatt kész, 0 Ft induló költséggel.